
😃🌞♎️👫☕️🍵🎾🎧
I am currently a Ph.D. student major in Control Science and Engineering at School of Artificial Intelligence and Robotics, Hunan University (HNU), working under the supervision of Prof. Min Liu and Prof. Yaonan Wang. My research interest lies in robot vision, particularly in multimodal learning for industrial robots. Before entering Hunan University, I received my M.Eng. (supervised by Prof. Kai Hu and Prof. Xieping Gao) and B.S. degrees from School of Computer Science, Xiangtan University (XTU) in 2023 and 2020, and underwent over three-year research on medical image analysis. (Contact me: svyj@hnu.edu.cn)
🔍 Research Interests
- Multimodal Industrial Anomaly Detection: MIAD
- Vision-Language-Action Models: VLA
- Medical Image Analysis
🔥 Recent Updates
📝 Latest Works
-
[Oct. 2025] 📃 Our article on “Point Cloud Registration” was submitted to IEEE T-CSVT.
-
[Sep. 2025] 📃 Our article on “Few-Shot Strip Steel Surface Defect Segmentation” was submitted to IEEE T-IM.
-
[Sep. 2025] 📃 Our article on “Continual Learning-based Multimodal Anomaly Detection” was submitted to IEEE T-IP.
-
[Aug. 2025] 📃 Our article on “Semi-Supervised Soldering Defect Detection” was submitted to IEEE T-IM.
-
[Aug. 2025] 📃 Our article on “Multi-View Multi-class Anomaly Detection” was submitted to IEEE T-CSVT.
-
[Jul. 2025] 📃 Our article on “Surface Inspection Viewpoint Planning” was submitted to IEEE/ASME T-Mech.
-
[Jun. 2025] 📃 Our article on “Neural Architecture Search for Surface Defect Detection” was submitted to IEEE/ASME T-Mech.
-
[Jun. 2025] 📃 Our article on “Few-shot Unified Multimodal Industrial Anomaly Detection” was submitted to IEEE T-MM.
-
[May. 2025] 📃 Our article on “Training-free Unified Multimodal Anomaly Detection” was submitted to IEEE T-PAMI.
🎉 Nice News
-
[Oct. 2025] 📃 Our article on “Few-Shot Defect Segmentation” was accepted to IEEE/ASME T-Mech.
-
[Sep. 2025] 🎉 Our paper on “NAS-based Semantic Segmentation” was accepted to NeurIPS 2025.
-
[Sep. 2025] 🎉 Our article on “Multimodal Defect Detection with Missing Modalities” was accepted by IEEE/ASME T-Mech. [Project]
-
[Jun. 2025] 🎉 Our article on “Neural Architecture Search-based Aero-engine Blade Defect Detection” was accepted by SCIENTIA SINICA Informationis (中国科学: 信息科学). [PDF]
-
[Jun. 2025] 🎉 Our paper on “Prompt-driven Person Re-ID” was accepted by ICCV 2025. [Poster] [arXiv]
-
[Apr. 2025] 🎉 Our article on “Multi-View Industrial Anomaly Detection” was accepted by IEEE/ASME T-Mech (TMECH/AIM Focused Section). [PDF]
-
[Mar. 2025] 🎉 Our article on “Few-Shot Defect Segmentation” was accepted by IEEE T-ASE. [PDF]
-
[Dec. 2024] 🎉 Our article on “Multimodal Retinal Image Analysis” was accepted by IEEE T-IM. [PDF] [Project]
-
[Nov. 2024] 🎉 Our article on “Weakly Supervised Surface Defect Localization” was accepted by IEEE T-IM. [PDF] [Project]
-
[Apr. 2023] 🎓 Svy.J graduated from XTU and was conferred M.Eng. degree.
-
[Apr. 2023] 🌟 Svy.J was awarded the 28th “Principal Scholarship” of XTU.
-
[Mar. 2023] 🌟 Svy.J was awarded the title of “Excellent Graduates” of Hunan, China.
-
[Mar. 2023] 🌟 Svy.J was awarded the title of “Excellent Graduates” of XTU.
-
[Jan. 2023] 🎉 Our article on “Retinal Layer Segmentation in OCT” was accepted by the Journal of Software (软件学报). [PDF]
-
[Oct. 2022] 🌟 Svy.J was awarded the “Special Scholarship” again with the rank of 1/70.
-
[Sep. 2022] 🌟 Svy.J was awarded the “China National Scholarship”.
-
[Jul. 2022] 🎉 Our article on “Biomarkers Segmentation in OCTA” was accepted by IEEE T-IM. [PDF] [Project]
-
[Oct. 2021] 🌟 Svy.J was awarded the “Xinhualian Group Education Scholarship”.
-
[Oct. 2021] 🌟 Svy.J was awarded the “Special Scholarship” with the rank of 1/70.
-
[Dec. 2020] 🏆 Svy.J won the 3rd prize in the 4th ISICDM in “Challenge 3: Segmentation of Pulmonary Tissues” with his teammates Tongtong Liu (Now a Ph.D. student at SCUT) and Fucai Wu (Now a engineer at LUSTER). [ISICDM 2020]
-
[Oct. 2020] 🌟 Svy.J was awarded the “First Class Scholarship” with the rank of 1/70.
📚 Publications
† Co-first Author, * Corresponding Author
📑 Peer-Reviewed Publications
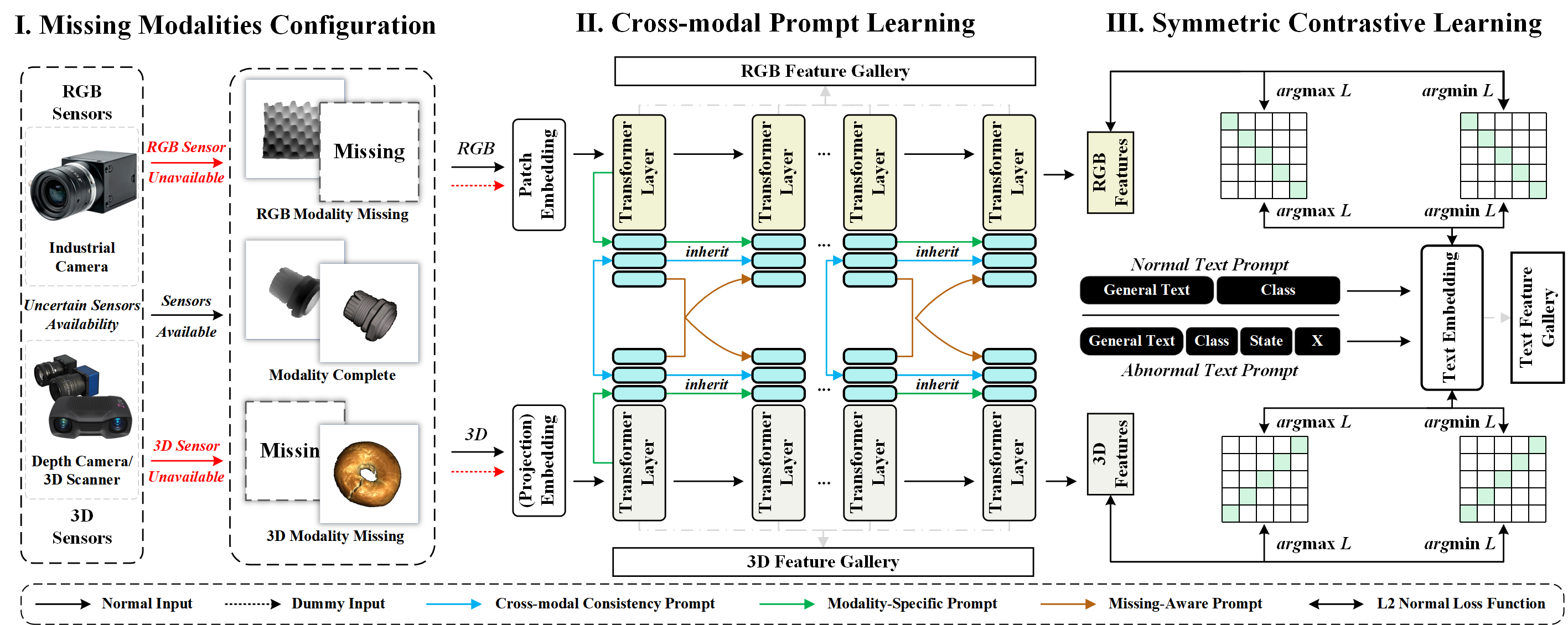
Resilient Multimodal Industrial Surface Defect Detection with Uncertain Sensors Availability
Shuai Jiang, Yunfeng Ma, Jingyu Zhou, Yuan Bian, Yaonan Wang, and Min Liu*
IEEE/ASME Transactions on Mechatronics (T-Mech), 2025
arXiv | PDF | Project
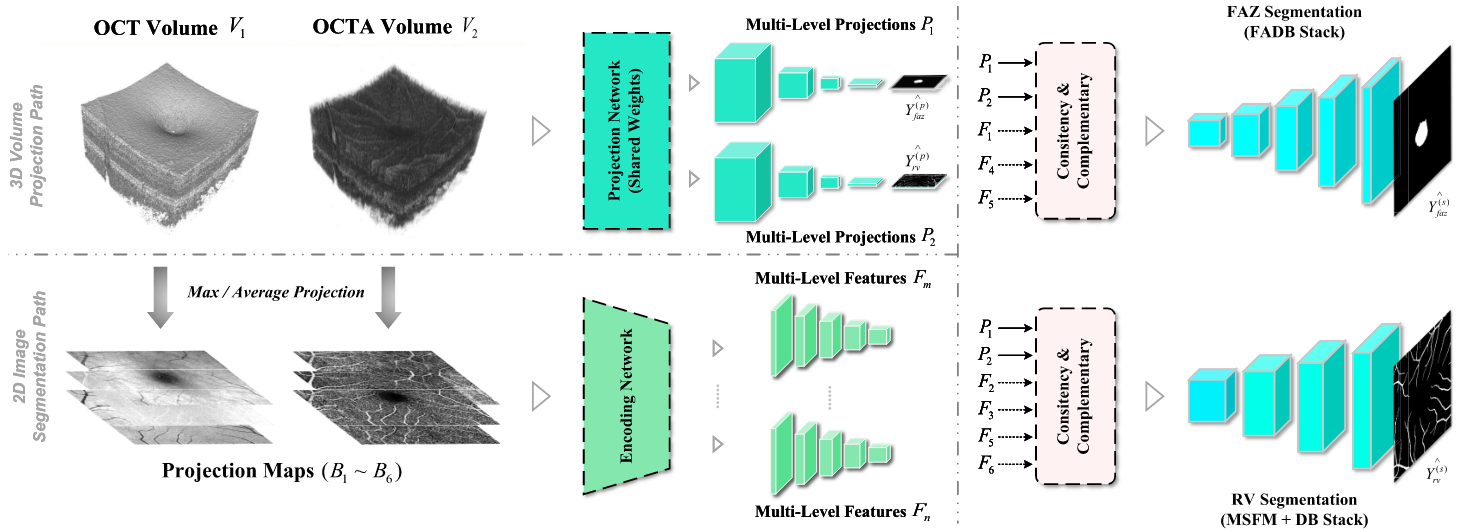
Joint Segmentation of FAZ and RVs in OCTA Images with Auxiliary 3D Image Projection Learning
Shuai Jiang, Kai Hu*, Yuan Zhang, and Xieping Gao
IEEE Transactions on Instrumentation and Measurement (T-IM), 2024
PDF | Project
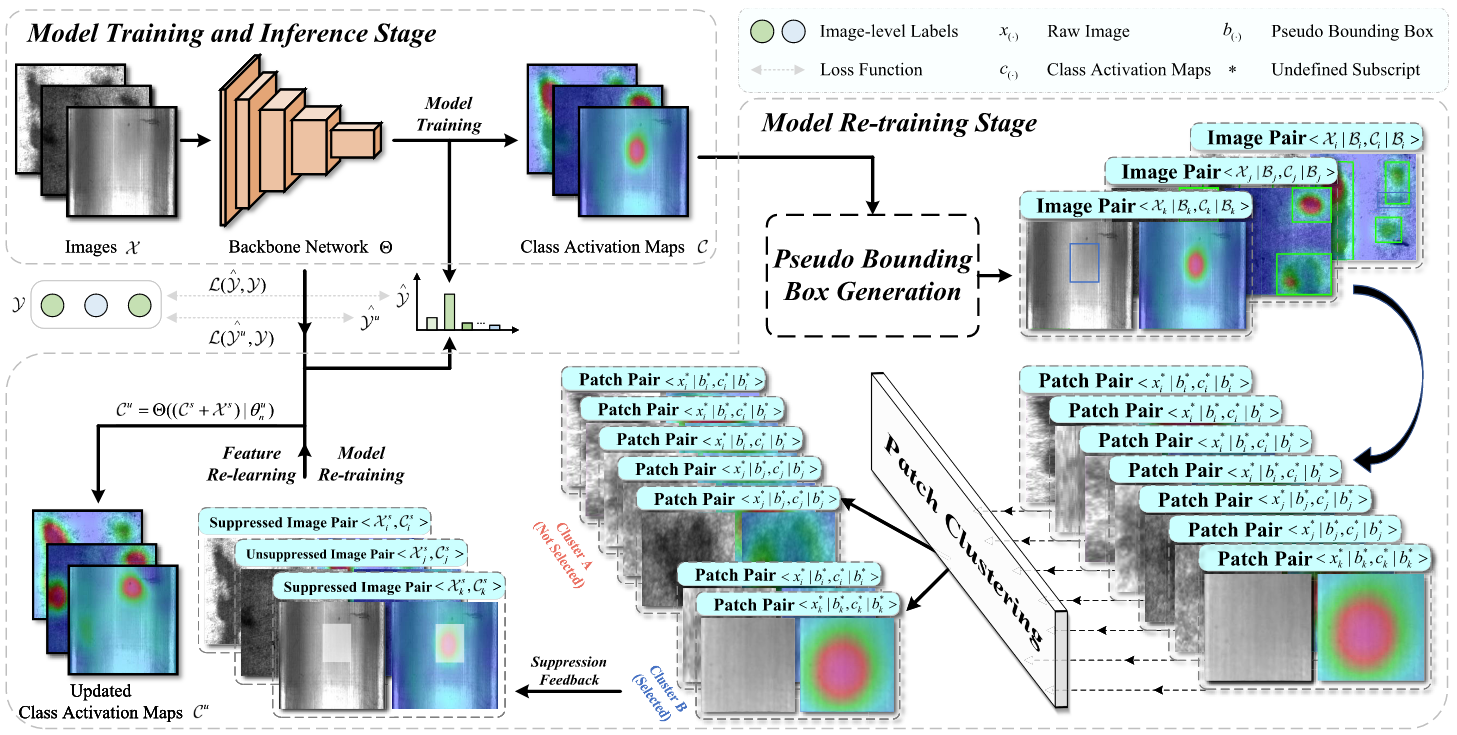
Category-agnostic Cluster-guided Selective Suppression for Weakly Supervised Surface Defect Localization
Shuai Jiang, Min Liu*, Yuxi Liu, Yunfeng Ma, and Yaonan Wang
IEEE Transactions on Instrumentation and Measurement (T-IM), 2024
PDF | Project
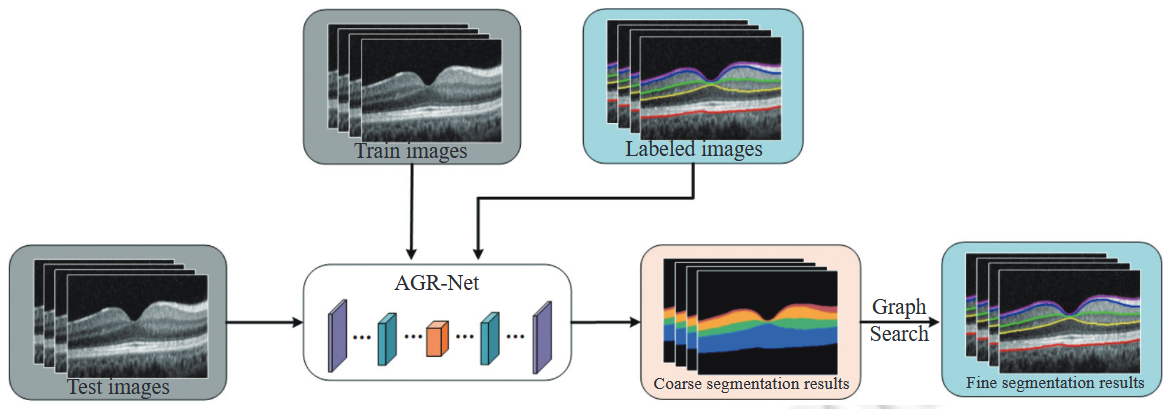
Segmentation of Retinal Layer Boundary in OCT Images Based on End-to-end Deep Neural Network and Graph Search
Kai Hu (M.E. Supervisor), Shuai Jiang, Dong Liu, and Xieping Gao*
Journal of Software (软件学报), 2023
PDF
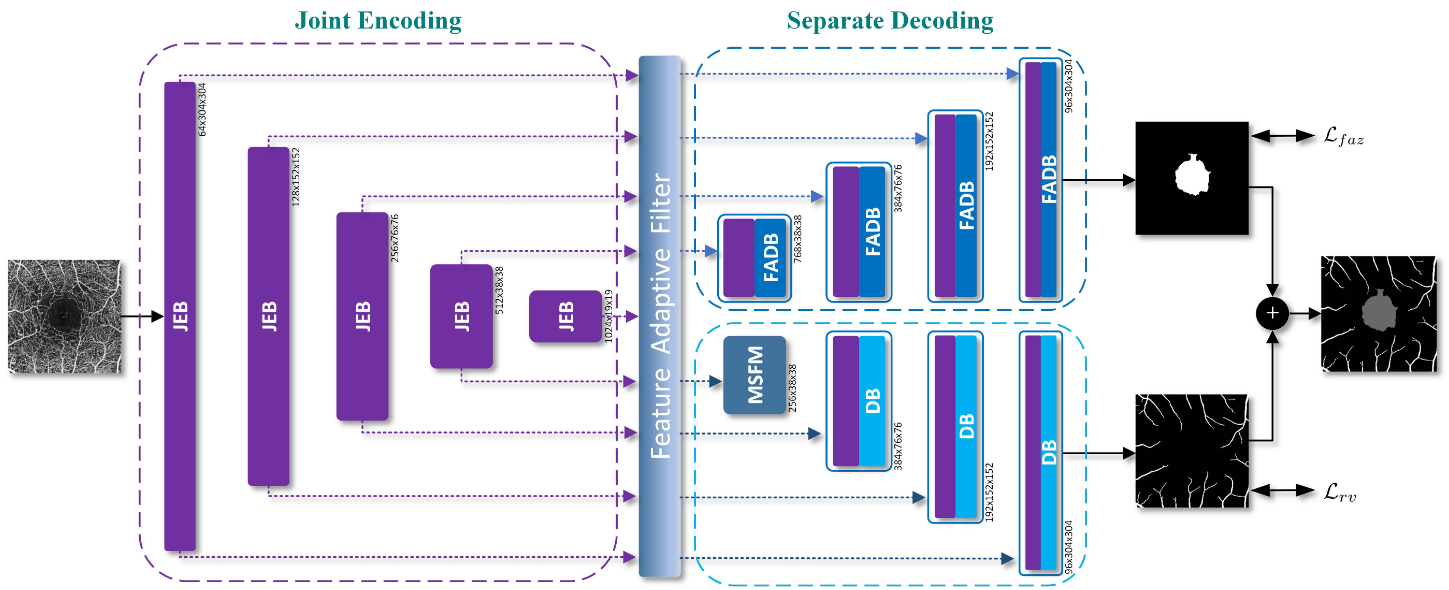
Joint-Seg: Treat Foveal Avascular Zone and Retinal Vessel Segmentation in OCTA Images as a Joint Task
Kai Hu (M.E. Supervisor), Shuai Jiang, Yuan Zhang, Xuanya Li, and Xieping Gao*
IEEE Transactions on Instrumentation and Measurement (T-IM), 2022
PDF | Project
📄 Co-authored Peer-Reviewed Publications
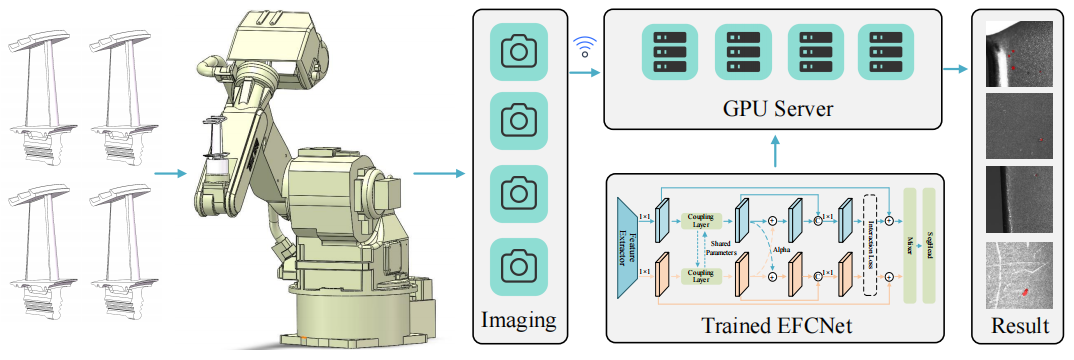
Efficient Feature Coupling for Industrial Few-shot Defect Segmentation
Yunfeng Ma, Min Liu*, Shuai Jiang, Jingyu Zhou, Yuan Bian, and Yaonan Wang
IEEE/ASME Transactions on Mechatronics (T-Mech), 2025
PDF
Searching Efficient Semantic Segmentation Architectures via Dynamic Path Selection
Yuxi Liu†, Min Liu†, Shuai Jiang, Yi Tang*, and Yaonan Wang
The Thirty-ninth Annual Conference on Neural Information Processing Systems (NeurIPS), 2025
PDF | Poster
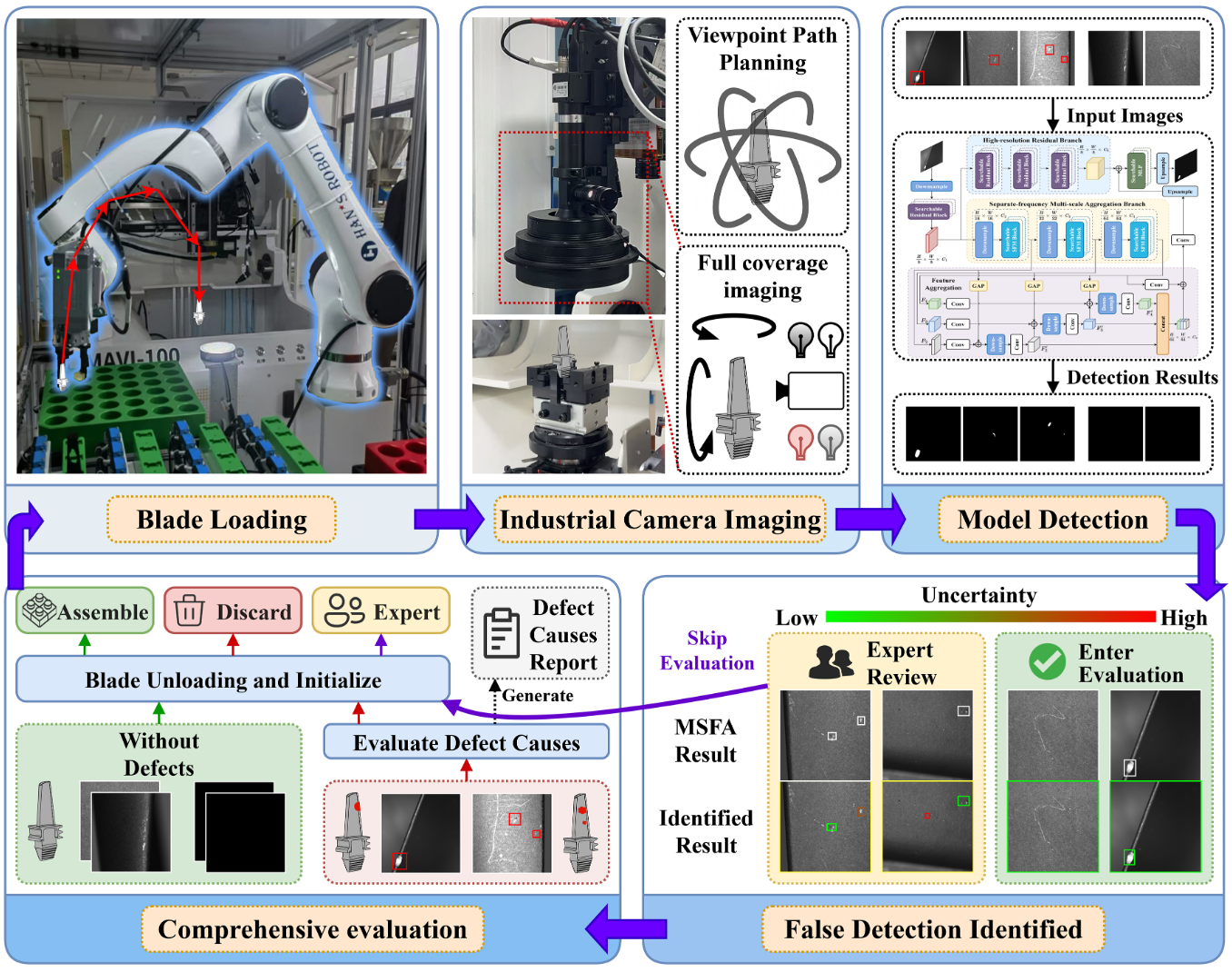
Neural Architecture Search-based Detection Method and System for Aero-engine Blade Surface Defects
Xihang Cheng†, Xiangfei Meng†, Min Liu*, Yuxi Liu, Yunfeng Ma, Shuai Jiang, and Yaonan Wang
SCIENTIA SINICA Informationis (中国科学: 信息科学), 2025
PDF
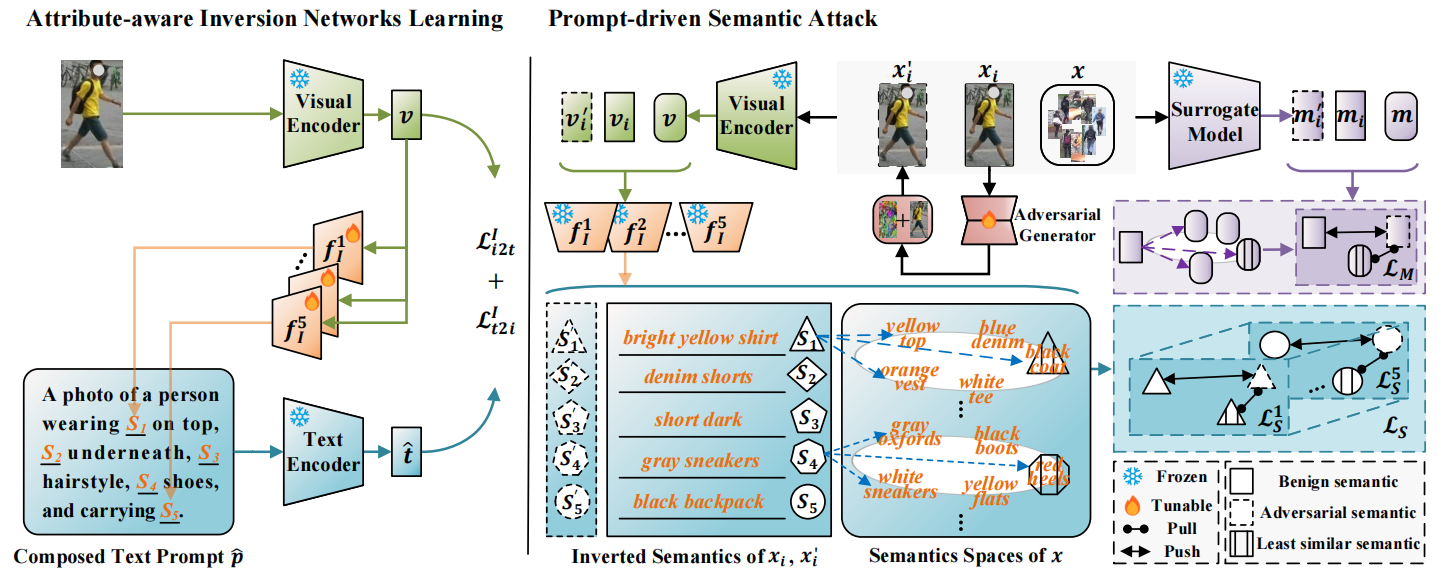
Prompt-driven Transferable Adversarial Attack on Person Re-Identification with Attribute-aware Textual Inversion
Yuan Bian, Min Liu*, Yunqi Yi, Xueping Wang, Shuai Jiang, Yaonan Wang
IEEE/CVF International Conference on Computer Vision (ICCV), 2025
arXiv | Poster
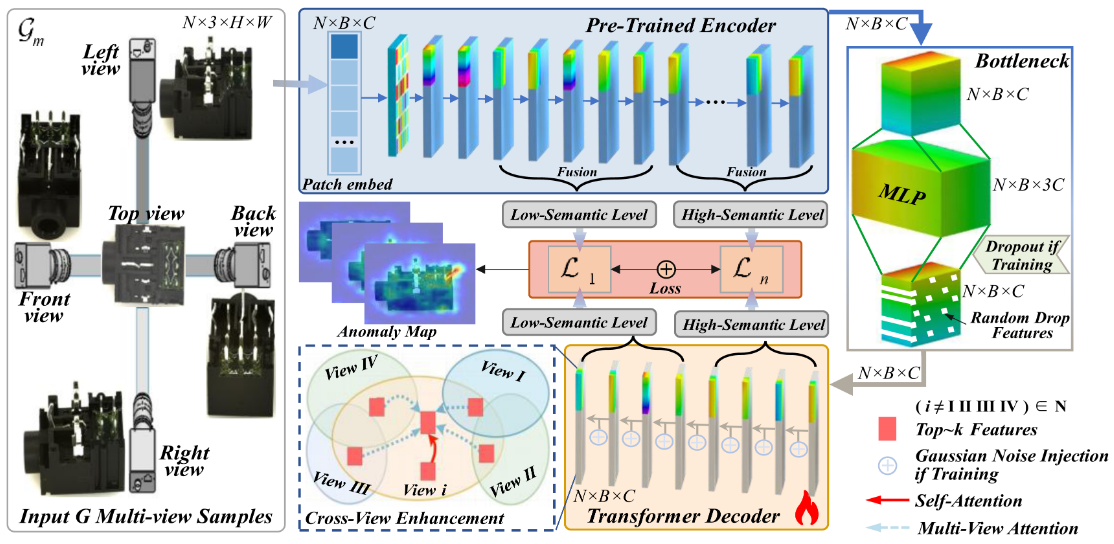
Multi-View Attention Guided Feature Learning for Unsupervised Surface Defect Detection
Jingyu Zhou, Min Liu*, Yunfeng Ma, Shuai Jiang, and Yaonan Wang
IEEE/ASME Transactions on Mechatronics (T-Mech), 2025
PDF
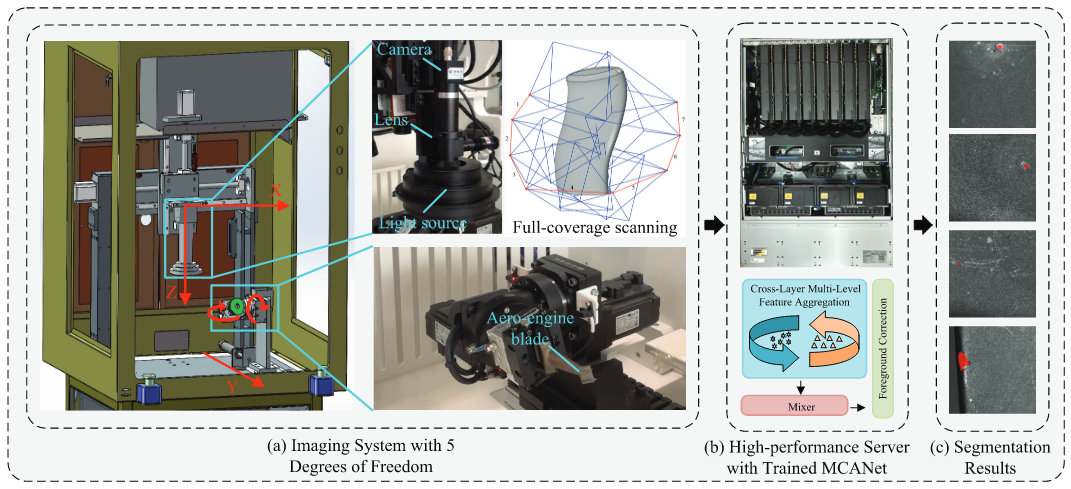
Multi-Context Aggregation Network with Foreground Correction for Automated Few-Shot Defect Segmentation
Yunfeng Ma, Min Liu*, Shuai Jiang, Xueping Wang, Yuan Bian, and Yaonan Wang
IEEE Transactions on Automation Science and Engineering (T-ASE), 2025
PDF
📃 Manuscripts in Peer Review
-
SCAP: Semantic Prototype Alignment for Robust Point Cloud Registration
Jingyu Zhou, Yunfeng Ma, Shuai Jiang, Yaonan Wang, and Min Liu*
IEEE Transactions on Circuits and Systems for Video Technology (T-CSVT), 2025 -
Edge-guided Semantic Cross-Matching Network for Few-Shot Strip Steel Surface Defect Segmentation
Zekai Yao†, Yunfeng Ma†, Min Liu*, Shuai Jiang, Yingmei He, and Yaonan Wang
IEEE Transactions on Instrumentation and Measurement (T-IM), 2025 -
COLA: Unsupervised Continual Learning for Zero-shot Multimodal Anomaly Detection
Yunfeng Ma†, Shuai Jiang†, Min Liu*, Jingyu Zhou, Xueping Wang, and Yaonan Wang
IEEE Transactions on Image Processing (T-IP), 2025 -
EGCR-Net: Edge-Guided Cross-Region Network for Semi-Supervised Soldering Defect Detection
Yaoyi Cai, Dan Huang, ZhiXun Li, Yunfeng Ma, Shuai Jiang, Zekai Yao*, and Min Liu*
IEEE Transactions on Instrumentation and Measurement (T-IM), 2025 (In Major Revision) -
Cross-View Dynamic Learning-Based Multi-Class Industrial Anomaly Detection
Jingyu Zhou, Yunfeng Ma, Shuai Jiang, Yaonan Wang, and Min Liu*
IEEE Transactions on Circuits and Systems for Video Technology (T-CSVT), 2025 (In Major Revision) -
3D Imaging Optical Path-Guided Viewpoint Planning Method for Free-Form Surface Inspection
Jingyu Zhou†, Yunfeng Ma†, Zhenhai Li, Min Liu*, Shuai Jiang, and Yaonan Wang
IEEE/ASME Transactions on Mechatronics (T-Mech), 2025 (In Major Revision) -
Automated Neural Architecture Design for Industrial Defect Detection
Yuxi Liu†, Yunfeng Ma†, Yi Tang, Min Liu*, Shuai Jiang, and Yaonan Wang
IEEE/ASME Transactions on Mechatronics (T-Mech), 2025 (In Major Revision)
arXiv -
Unified Multimodal Industrial Anomaly Detection via Few Normal Samples
Shuai Jiang, Min Liu*, Yunfeng Ma, Jingyu Zhou, and Yaonan Wang
IEEE Transactions on Multimedia (T-MM), 2025 -
ZUMA: Training-free Zero-shot Unified Multimodal Anomaly Detection
Yunfeng Ma, Min Liu*, Shuai Jiang, Jingyu Zhou, Yuan Bian, Xueping Wang, and Yaonan Wang
IEEE Transactions on Pattern Analysis and Machine Intelligence (T-PAMI), 2025 (In Major Revision)
🎖 Honors and Awards
- Excellent Graduates, Hunan Provincial Department of Education, 2023.
- Excellent Graduates, Xiangtan University, 2023.
- Principal Scholarship, Xiangtan University, 2023.
- China National Scholarship, Ministry of Education of the People’s Republic of China, 2022.
- Special Scholarship, Xiangtan University, 2022 / 2021.
🧑🤝🧑 Services
- Journal Reviewer: T-MI, T-IM, J-BHI, Scientific Data, IEEE Access
- Conference Reviewer: NeurIPS, CVPR, ICCV, AAAI, ACMMM, ICASSP, ICME
📖 Educations
- Sep. 2023 - Now, Hunan University, Ph.D. Candidate.
- Oct. 2020 - Jun. 2023, Xiangtan University, M.E.
- Sep. 2016 - Jun. 2020, Xiangtan University, B.S.