Multimodal Industrial Anomaly Detection(多模态异常检测)
数据模态
目前多模态检测算法涉及的数据模态主要(或者说仅仅)有RGB图像、单视角点云(深度图)、文本
数据集
常见的数据集包括如 MVTec 3D-AD、EyeCandies 和 Real3D-AD等
| 数据集名称 | 类别数 | 规模 | 数据模态 | 来源 | 应用场景 | 官方链接 |
|---|---|---|---|---|---|---|
| MVTec 3D-AD | 10 | ~4K | RGB-D图像、点云数据 | 真实采集的工业场景数据 | 工业零件表面缺陷检测(如金属、塑料制品) | https://www.mvtec.com/company/research/datasets/mvtec-3d-ad |
| EyeCandies | 7 | ~10K | RGB图像、点云数据 | 高度逼真的合成数据,模拟复杂环境 | 算法鲁棒性测试,生成复杂背景和光照下的异常 | https://github.com/emmanuelbranlard/eye-candies |
| Real3D-AD | 10 | ~1.5K | RGB-D、点云、多视角图像 | 真实场景采集,覆盖多样光照和角度 | 日常物体异常检测(如电子设备、家具) | https://github.com/Real3DAD/Real3D-AD |
检测算法(基于 RGB + Point Cloud)
(写在前面)PatchCore
论文:Towards Total Recall in Industrial Anomaly Detection (CVPR 2022)[注:后面大量的工作都是基于PatchCore的模式]
关键思想:Maximally Representative Memory Bank of Nominal Patch-features.
Memory Bank 机制
MemoryBank 建立在一个具有内存检索和更新机制的内存存储器上,能够总结过去的事件。通过不断的记忆更新不断进化,通过合成以前的信息,随着时间的推移理解,根据经过的时间和记忆的相对重要性来忘记和强化记忆。每次出现查询请求时,都会遍历一遍历史对话记录,然后当前查询的内容遗忘保留率 s+1
参考链接:
MemoryBank:Enhancing Large Language Models with Long-Term Memory_memory bank-CSDN博客
(艾宾浩斯记忆曲线有无数学模型? - 知乎 (zhihu.com)
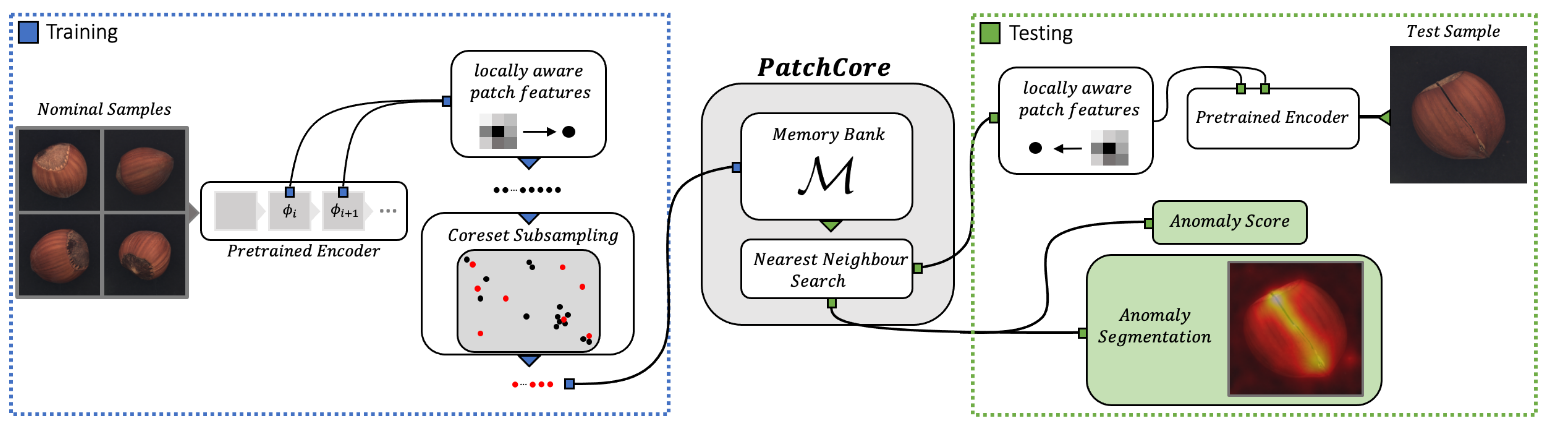
Back to Features (BTF aka. 3D-ADS)
论文:Back to the feature: classical 3d features are (almost) all you need for 3d anomaly detection (CVPRW 2023)
核心思想:CNN (RGB图像特征提取)+ FPFH (点云深度特征提取)
x# Model Fitting.## 1. Extracting Train Features and Fusion.for (rgb, pc), _ in tqdm(train_loader): ### (1) Extracting RGB Patch Features. rgb_patch = self.deep_feature_extractor(rgb) # e.g., wide_resnet50_2 ### (2) Extracting FPFH (Fast Point Feature Histogram) Patch Features. unorganized_pc = organized_pc_to_unorganized_pc(pc) unorganized_pc_no_zeros = unorganized_pc[np.nonzero(unorganized_pc), :] o3d_pc = o3d.geometry.PointCloud(o3d.utility.Vector3dVector(unorganized_pc_no_zeros)) ### (3) Normal Estimation (法线估计) radius_normal = voxel_size * 2 o3d_pc.estimate_normals(o3d.geometry.KDTreeSearchParamHybrid(radius=radius_normal, max_nn=30)) ### (4) Geometric Feature Representation (几何特征描述) radius_feature = voxel_size * 5 pcd_fpfh = o3d.pipelines.registration.compute_fpfh_feature( \ o3d_pc, o3d.geometry.KDTreeSearchParamHybrid(radius=radius_feature, max_nn=100) ) fpfh = pcd_fpfh.data.T fpfh_patch = np.zeros((unorganized_pc.shape[0], fpfh.shape[1]), dtype=fpfh.dtype) fpfh_patch[nonzero_indices, :] = fpfh ### (5) Add Sample to Memory Bank. self.patch_lib.append(torch.cat([rgb_patch, fpfh_patch], dim=1))
## 2. Get Coreset for Each Feature Extractor.for method_name, method in self.methods.items(): if self.f_coreset < 1: ### Get n coreset idx for given patch_lib transformer = random_projection.SparseRandomProjection(eps=eps) patch_lib = torch.tensor(transformer.fit_transform(z_lib)) select_idx = 0 last_item = z_lib[select_idx:select_idx + 1] coreset_idx = [torch.tensor(select_idx)] min_distances = torch.linalg.norm(z_lib - last_item, dim=1, keepdims=True) for _ in tqdm(range(n - 1)): distances = torch.linalg.norm(z_lib - last_item, dim=1, keepdims=True) # broadcasting step min_distances = torch.minimum(distances, min_distances) # iterative step select_idx = torch.argmax(min_distances) # selection step coreset_idx.append(select_idx) coreset_idx = torch.stack(coreset_idx) self.patch_lib = self.patch_lib[self.coreset_idx] xxxxxxxxxx# Model Inference.for (rgb, pc), mask, label in tqdm(test_loader): ## 1. Extracting Features. rgb_patch = self.deep_feature_extractor(rgb) depth_patch = get_fpfh_features(pc) patch = torch.cat([rgb_patch, depth_patch], dim=1) feature_map_dims = torch.cat([rgb_patch[0], depth_patch], dim=1).shape[-2:] ## 2. Compute Aomaly Score and Segmentation Map. dist = torch.cdist(patch, self.patch_lib) min_val, min_idx = torch.min(dist, dim=1) s_idx, s_star = torch.argmax(min_val), torch.max(min_val) ### (1) Re-weighting m_test = patch[s_idx].unsqueeze(0) # anomalous patch m_star = self.patch_lib[min_idx[s_idx]].unsqueeze(0) # closest neighbour w_dist = torch.cdist(m_star, self.patch_lib) # find knn to m_star pt.1 _, nn_idx = torch.topk(w_dist, k=self.n_reweight, largest=False) # pt.2 m_star_knn = torch.linalg.norm(m_test - self.patch_lib[nn_idx[0, 1:]], dim=1) # Eq. 7 in paper ### (2) Softmax normalization trick as in transformers. ### (3) As the patch vectors grow larger, their norm might differ a lot. exp(norm) can give infinities. D = torch.sqrt(torch.tensor(patch.shape[1])) w = 1 - (torch.exp(s_star / D) / (torch.sum(torch.exp(m_star_knn / D)))) s = w * s_star ### (4) Calculate Segmentation Map s_map = min_val.view(1, 1, *feature_map_dims) s_map = torch.nn.functional.interpolate(s_map, size=(self.image_size, self.image_size), mode='bilinear') s_map = self.blur(s_map)Shape-Guided Dual-Memory Learning
论文:Shape-Guided Dual-Memory Learning for 3D Anomaly Detection (ICML 2023)
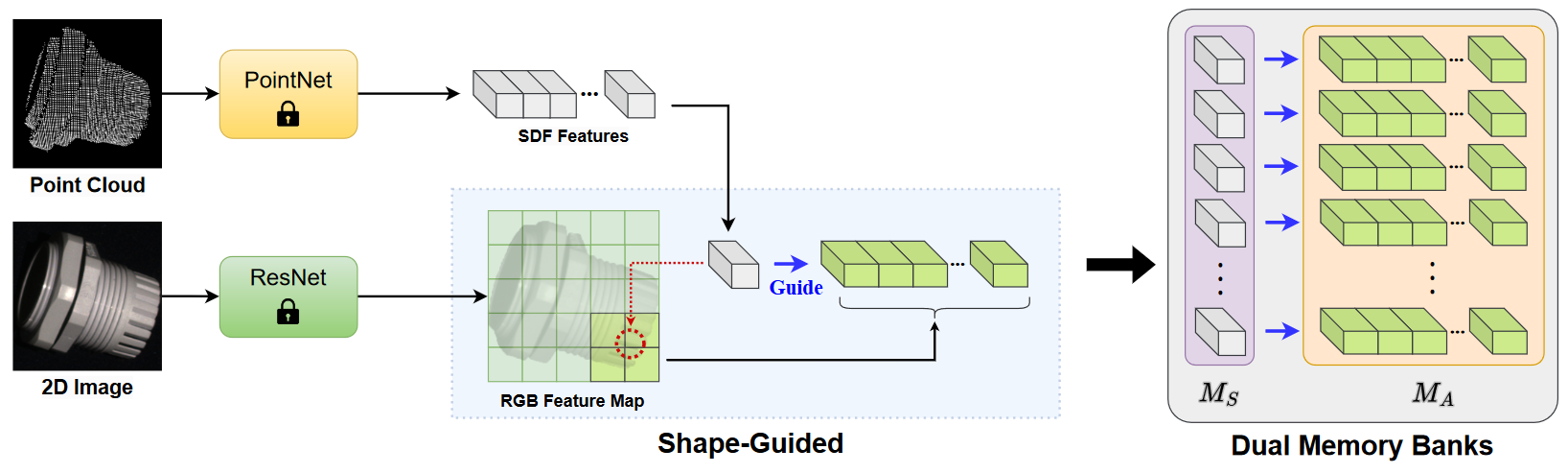
xxxxxxxxxx# Model Fitting.## 1. Model Instantiation.self.methods = RGBSDFFeatures(conf, pro_limit, output_dir)self.rgb_feature_extractor = RGB_Model()self.sdf = SDFFeature() # include self.encoder = encoder_BN(), self.NIF = local_NIF()
## 2. Extract RGB and SDF Features.for train_data_id, (img, pc, _) in enumerate(tqdm(data_loader): rgb_feature_maps = self.rgb_feature_extractor(img) # Extract RGB features. sdf_feature, rgb_feature_indices_patch = self.sdf.get_feature(pc, train_data_id) # Extract SDF features. self.sdf_patch_lib.append(sdf_feature) self.rgb_patch_lib.append(rgb_patch_size28) self.rgb_f_idx_patch_lib.extend(rgb_feature_indices_patch)
## 3. Foreground Subsampling.self.sdf_patch_lib = torch.cat(self.sdf_patch_lib, 0)self.rgb_patch_lib = torch.cat(self.rgb_patch_lib, 0)use_f_idices = torch.unique(torch.cat(self.rgb_f_idx_patch_lib, dim=0))self.rgb_patch_lib = self.rgb_patch_lib[use_f_idices] # Remove unused RGB featuresxxxxxxxxxx# Model Inference.## 1. Generate Predictions for alignment.for align_data_id, (img, pc, _) in enumerate(data_loader): if align_data_id < 25: '''RGB patch''' rgb_feature_maps = self.rgb_feature_extractor(img) rgb_map, rgb_s = self.Dict_compute_rgb_map(rgb_feature_maps, rgb_features_indices, lib_idices, mode='alignment') '''SDF patch''' feature, rgb_features_indices = self.sdf.get_feature(pc, align_data_id, 'test') NN_feature, Dict_features, lib_idices, sdf_s = self.Find_KNN_feature(feature, mode='alignment') sdf_map = self.sdf.get_score_map(Dict_features, sample[1], sample[2]) '''Image_level predictions''' self.sdf_image_preds.append(sdf_s) self.rgb_image_preds.append(rgb_s) '''Pixel_level predictions''' self.rgb_pixel_preds.extend(rgb_map.flatten()) self.sdf_pixel_preds.extend(sdf_map.flatten())
## 2. Computing weight and bias for alignment with SDF and RGB distribution.### (1) Compute SDF distributionnon_zero_sdf_map = sdf_map[np.nonzero(sdf_map)]sdf_lower = np.mean(non_zero_sdf_map) - 3 * np.std(non_zero_sdf_map)sdf_upper = np.mean(non_zero_sdf_map) + 3 * np.std(non_zero_sdf_map)### (2) Compute RGB distributionnon_zero_rgb_map = rgb_map[np.nonzero(rgb_map)]rgb_lower = np.mean(non_zero_rgb_map) - 3 * np.std(non_zero_rgb_map)rgb_upper = np.mean(non_zero_rgb_map) + 3 * np.std(non_zero_rgb_map)### (3) Compute weight and bias for alignmentself.weight = (sdf_upper - sdf_lower) / (rgb_upper - rgb_lower)self.bias = sdf_lower - self.weight * rgb_lower
## 3. Extract testing features and predict.for test_data_id, (sample, mask, label) in enumerate(tqdm(test_loader): ### (1) RGB patch rgb_feature_maps = self.rgb_feature_extractor(img) rgb_map, rgb_s = self.Dict_compute_rgb_map(rgb_feature_maps, rgb_features_indices, lib_idices, mode='alignment') ### (2) SDF patch feature, rgb_features_indices = self.sdf.get_feature(pc, align_data_id, 'test') NN_feature, Dict_features, lib_idices, sdf_s = self.Find_KNN_feature(feature, mode='alignment') sdf_map = self.sdf.get_score_map(Dict_features, sample[1], sample[2]) ### (3) Predictions image_score = sdf_s * rgb_s # Image-level prediction new_rgb_map = rgb_map * self.weight + self.bias pixel_map = torch.maximum(new_rgb_map, sdf_map) # Pixel-level predictionMulti-3D-Memory (M3DM)
论文:Multimodal Industrial Anomaly Detection via Hybrid Fusion (CVPR 2023)
复现:M3DM复现记录 | “干杯( ゚-゚)っロ” (svyj.github.io)
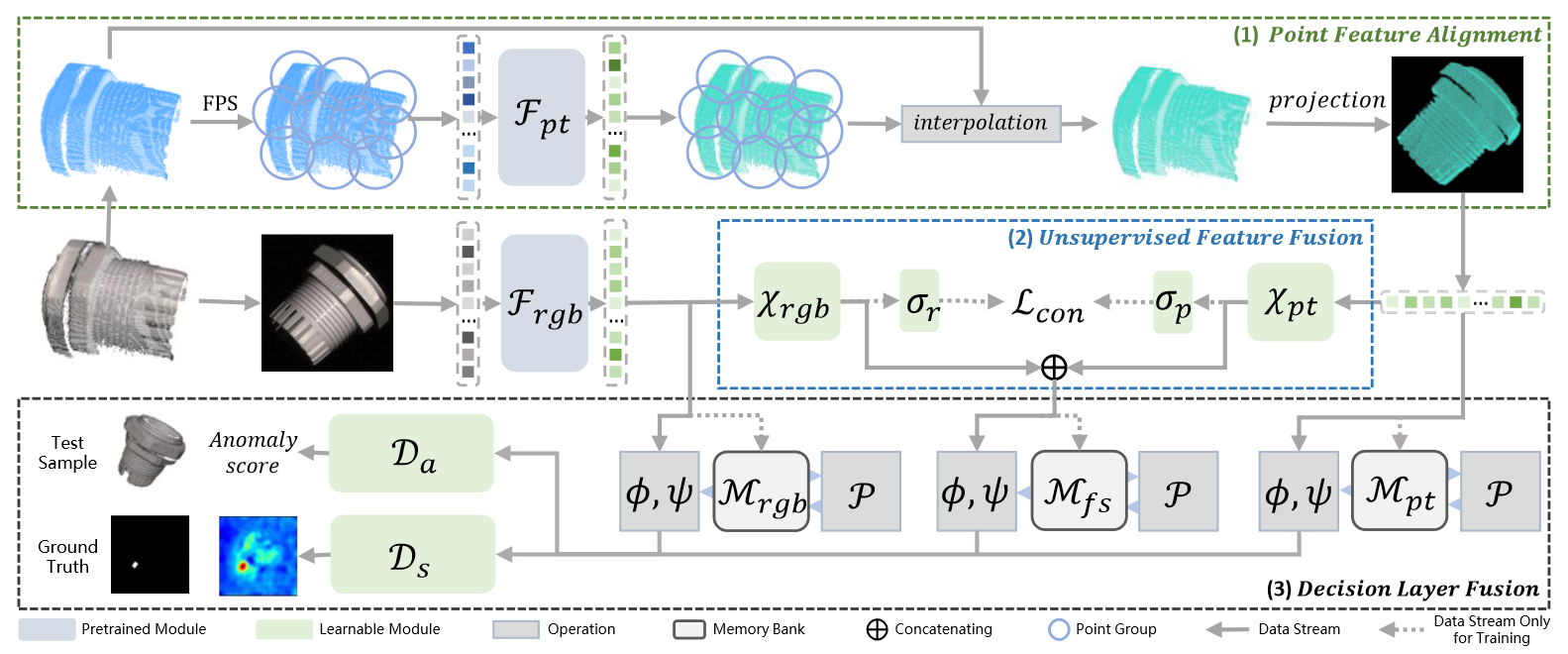
xxxxxxxxxx# Train UFF.for data_iter_step, (samples, _) in enumerate(metric_logger.log_every(data_loader, print_freq, header)): xyz_samples = samples[:,:,:1152].to(device, non_blocking=True) rgb_samples = samples[:,:,1152:].to(device, non_blocking=True) ## 1. Normalize q = nn.functional.normalize(q, dim=1) k = nn.functional.normalize(k, dim=1) ## 2. Gather All Targets, Einstein Sum is More Intuitive logits = torch.einsum('nc,mc->nm', [q, k]) / self.T N = logits.shape[0] # batch size per GPU labels = (torch.arange(N, dtype=torch.long) + N * torch.distributed.get_rank()).cuda() loss = nn.CrossEntropyLoss()(logits, labels) * (2 * self.T) # Contrastive Lossxxxxxxxxxx# Model Fitting.## 1. Extracting Train Features and Fusion.for sample, _ in tqdm(train_loader): ### (1) Extracting Train Features. ''' RGB backbone - vit_base_patch8_224_dino XYZ backbone - Point_MAE ''' rgb_feature_maps, xyz_feature_maps, _, _, _, interpolated_pc = \ self.deep_feature_extractor(rgb, xyz) ### (2) Feature Fusion. xyz_feature = self.xyz_mlp(self.xyz_norm(xyz_feature)) rgb_feature = self.rgb_mlp(self.rgb_norm(rgb_feature)) patch = torch.cat([xyz_feature, rgb_feature], dim=2) ### (3) Add Sample to Memory Bank. self.patch_lib.append(rgb_patch) ## 2. Get Coreset from Memory Bank.for method_name, method in self.methods.items(): if self.f_coreset < 1: self.coreset_idx = \ self.get_coreset_idx_randomp(self.patch_lib, n=self.f_coreset*self.patch_lib.shape[0])) self.patch_lib = self.patch_lib[self.coreset_idx] xxxxxxxxxx# Model Inference.for sample, mask, label, rgb_path in tqdm(test_loader): ## 1. Extracting Features. rgb_feature_maps, xyz_feature_maps, center, neighbor_idx, center_idx, interpolated_pc = \ self.deep_feature_extractor(rgb, xyz) ## 2. Feature Fusion. xyz_feature = self.xyz_mlp(self.xyz_norm(xyz_feature)) rgb_feature = self.rgb_mlp(self.rgb_norm(rgb_feature)) patch = torch.cat([xyz_feature, rgb_feature], dim=2) ## 3. Compute Aomaly Score and Segmentation Map. dist = torch.cdist(patch, self.patch_lib) # Calculate the distance between two vectors. min_val, min_idx = torch.min(dist, dim=1) # Anomaly s_idx, s_star = torch.argmax(min_val), torch.max(min_val) m_test = patch[s_idx].unsqueeze(0) # anomalous patch m_star = self.patch_lib[min_idx[s_idx]].unsqueeze(0) # closest neighbour w_dist = torch.cdist(m_star, self.patch_lib) # find knn to m_star pt.1 _, nn_idx = torch.topk(w_dist, k=self.n_reweight, largest=False) # pt.2 m_star_knn = torch.linalg.norm(m_test - self.patch_lib[nn_idx[0, 1:]], dim=1) D = torch.sqrt(torch.tensor(patch.shape[1])) w = 1 - (torch.exp(s_star / D) / (torch.sum(torch.exp(m_star_knn / D)))) s = w * s_star s_map = min_val.view(1, 1, *feature_map_dims) s_map = torch.nn.functional.interpolate(s_map, size=(self.image_size, self.image_size), mode='bilinear') s_map = self.blur(s_map) # segmentation mapComplementary Pseudo Multimodal Feature (CPMF)
论文:Complementary pseudo multimodal feature for point cloud anomaly detection (PR 2024)
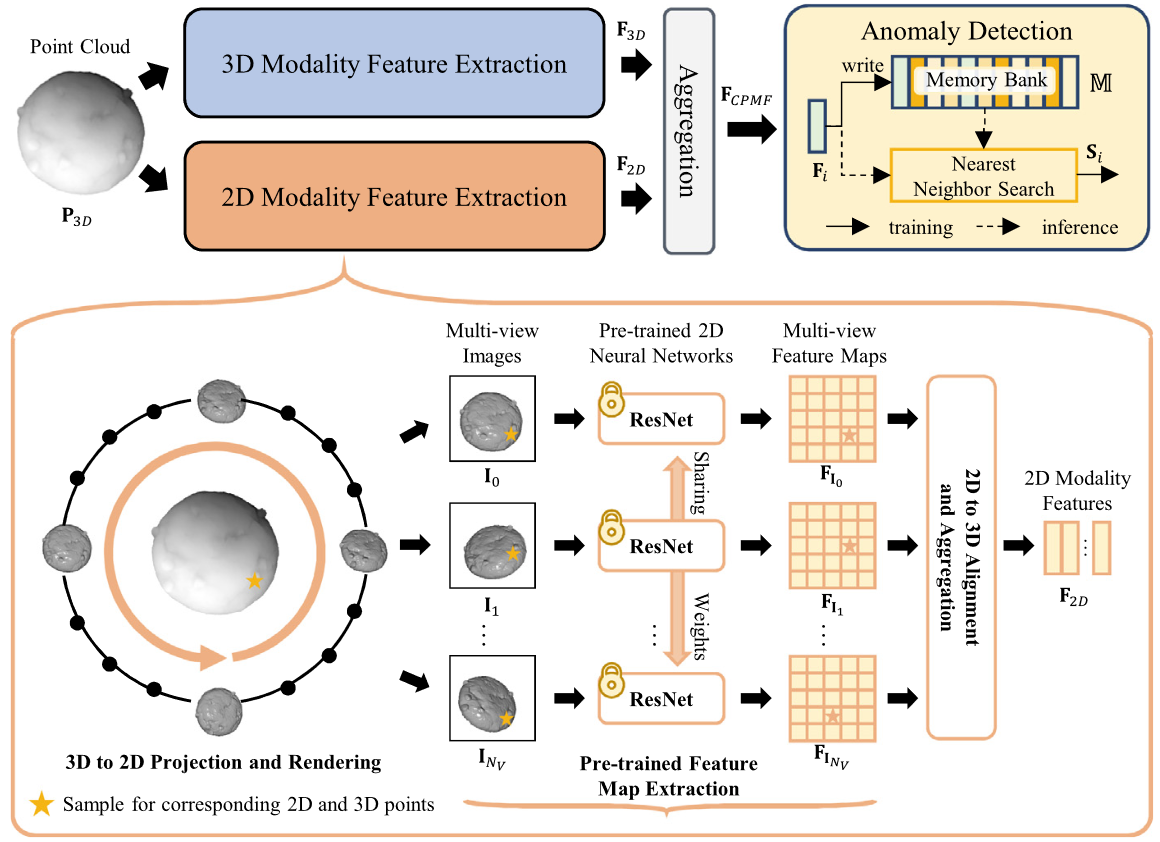
xxxxxxxxxx# Model Fitting (Multi-view PatchCore, same as M3DM except feature extraction).## 1. Extracting Train Features and Fusion.for (img, resized_organized_pc, features, view_images, view_positions), _, _ in tqdm(train_loader): ### (1) Extracting RGB Patch Features. if self.n_views > 0: view_invariant_features = self.calculate_view_invariance_feature(sample) # 视图不变性特征 view_invariant_features = F.normalize(view_invariant_features, dim=1, p=2) ### (2) Extracting FPFH Patch Features. fpfh_feature_maps = sample[2][0] fpfh_feature_maps = F.normalize(fpfh_feature_maps, dim=1, p=2) ### (3) Feature Fusion. if self.n_views > 0 and self.no_fpfh: concat_patch = torch.cat([view_invariant_features], dim=1) elif self.n_views > 0 and not self.no_fpfh: concat_patch = torch.cat([view_invariant_features, fpfh_feature_maps], dim=1) else: concat_patch = fpfh_feature_maps ### (4) Add Sample to Memory Bank. self.patch_lib.append(concat_patch)
## 2. Get Coreset from Memory Bank.self.patch_lib = torch.cat(self.patch_lib, 0) if self.f_coreset < 1: self.coreset_idx = self.get_coreset_idx_randomp(self.patch_lib, n=int(self.f_coreset * self.patch_lib.shape[0]), eps=self.coreset_eps, ) self.patch_lib = self.patch_lib[self.coreset_idx] # patch 本身的维度并没有变化,而是选择了稀疏的若干特征组成了新的特征库xxxxxxxxxx# Model Evaluation (Same as M3DM except feature extraction).## 1. Extracting Train Features and Fusion.for sample, mask, label in tqdm(test_loader): ### (1) Extracting RGB Patch Features. if self.n_views > 0: view_invariant_features = self.calculate_view_invariance_feature(sample) view_invariant_features = F.normalize(view_invariant_features, dim=1, p=2) ### (2) Extracting FPFH Patch Features. fpfh_feature_maps = sample[2][0] fpfh_feature_maps = F.normalize(fpfh_feature_maps, dim=1, p=2)
### (3) Feature Fusion. if self.n_views > 0 and self.no_fpfh: concat_patch = torch.cat([view_invariant_features], dim=1) elif self.n_views > 0 and not self.no_fpfh: concat_patch = torch.cat([view_invariant_features, fpfh_feature_maps], dim=1) else: concat_patch = fpfh_feature_maps
### (4) Compute Aomaly Score and Segmentation Map. (Same as M3DM) dist = torch.cdist(patch, self.patch_lib) min_val, min_idx = torch.min(dist, dim=1) s_idx, s_star = torch.argmax(min_val), torch.max(min_val) m_test = patch[s_idx].unsqueeze(0) # anomalous patch m_star = self.patch_lib[min_idx[s_idx]].unsqueeze(0) # closest neighbour w_dist = torch.cdist(m_star, self.patch_lib) # find knn to m_star pt.1 _, nn_idx = torch.topk(w_dist, k=self.n_reweight, largest=False) # pt.2 m_star_knn = torch.linalg.norm(m_test - self.patch_lib[nn_idx[0, 1:]], dim=1) D = torch.sqrt(torch.tensor(patch.shape[1])) w = 1 - (torch.exp(s_star / D) / (torch.sum(torch.exp(m_star_knn / D)))) s = w * s_star s_map = min_val.view(1, 1, *feature_map_dims) s_map = torch.nn.functional.interpolate(s_map, size=(self.image_size, self.image_size), mode='bilinear') s_map = self.blur(s_map) # segmentation map###
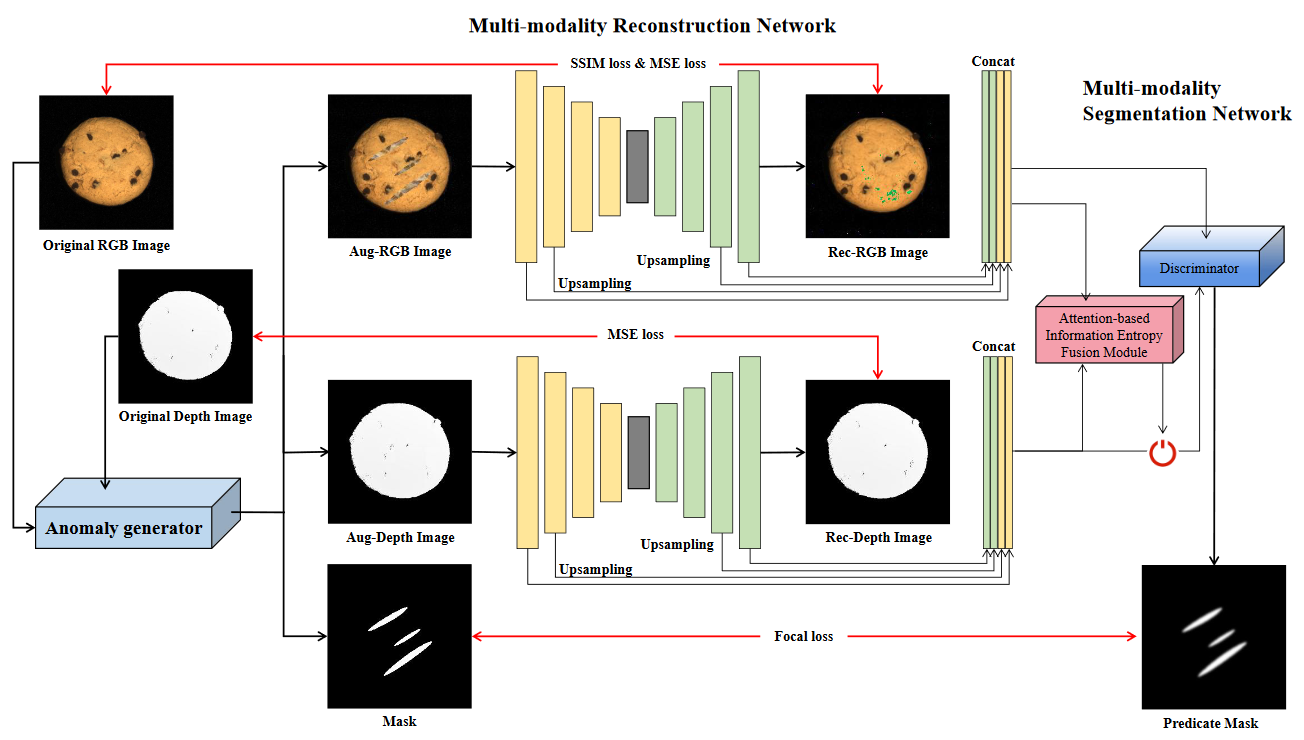
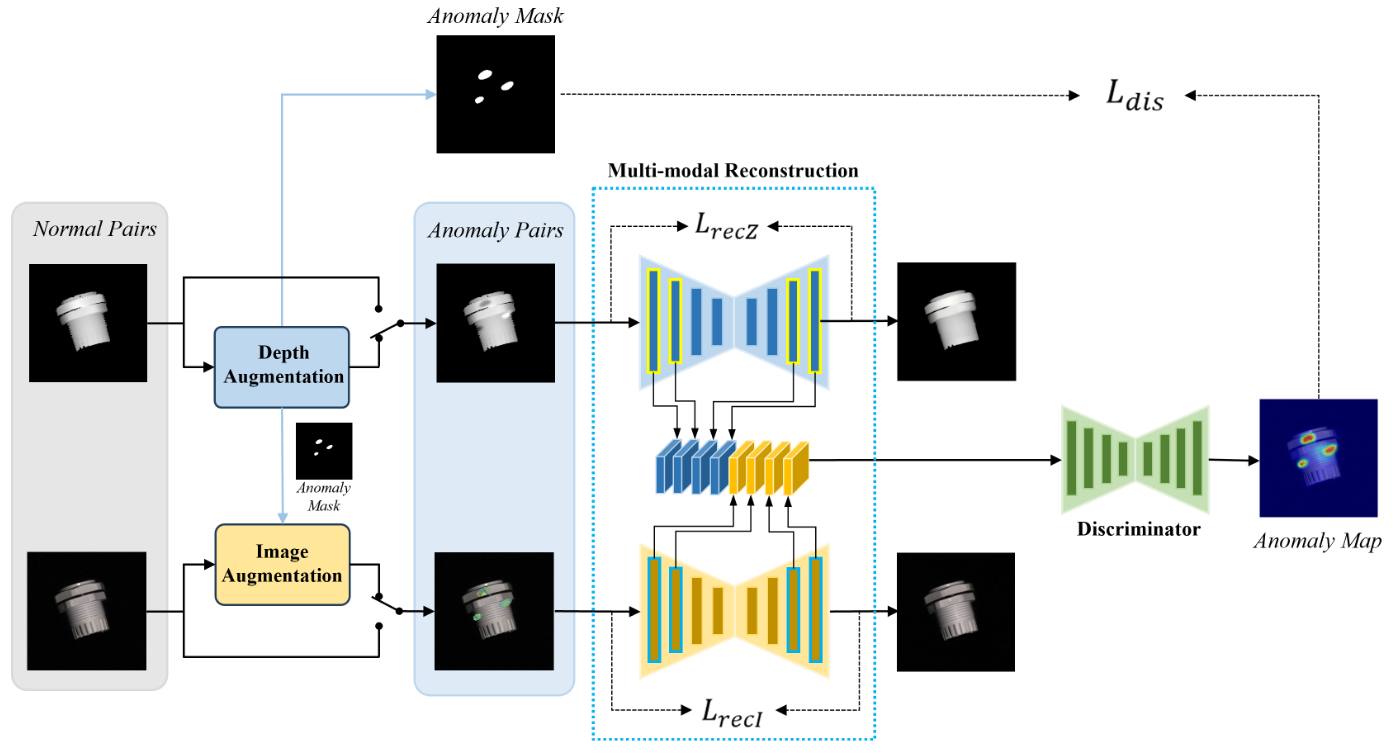
Multi-modality Reconstruction Network (EasyNet)
论文:EasyNet: An Easy Network for 3D Industrial Anomaly Detection (ACMMM 2023)
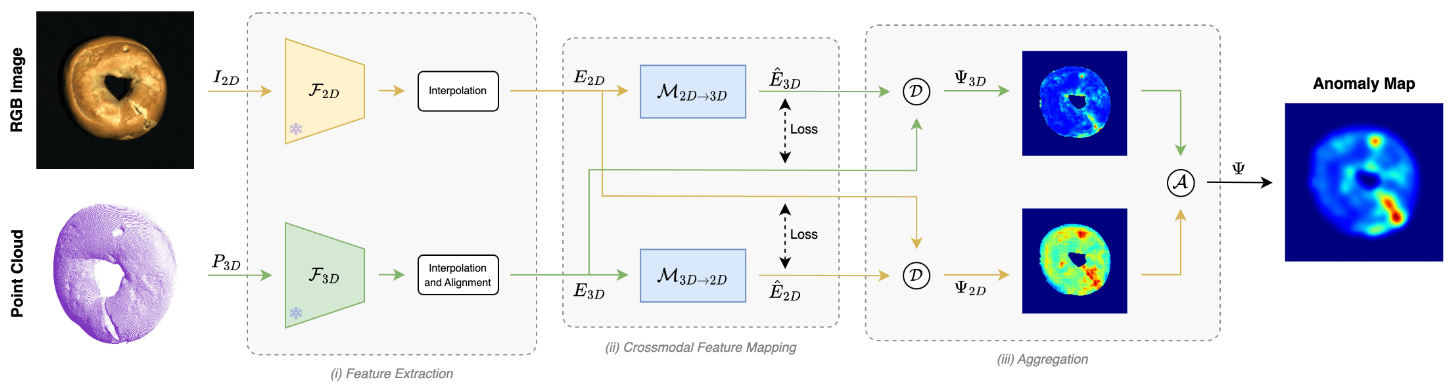
Crossmodal Feature Mapping (CFM)
论文:Multimodal Industrial Anomaly Detection by Crossmodal Feature Mapping (CVPR 2024)
xxxxxxxxxx# Training.## 1. Model Instantiation.Model instantiation.CFM_2Dto3D = FeatureProjectionMLP(in_features = 768, out_features = 1152)CFM_3Dto2D = FeatureProjectionMLP(in_features = 1152, out_features = 768)
## 2. Iteration.for (rgb, pc, _), _ in tqdm(train_loader): rgb_patch, xyz_patch = feature_extractor.get_features_maps(rgb, pc) rgb_feat_pred = CFM_3Dto2D(xyz_patch) xyz_feat_pred = CFM_2Dto3D(rgb_patch) ## 3. Losses.loss_3Dto2D = 1 - metric(xyz_feat_pred[~xyz_mask], xyz_patch[~xyz_mask]).mean()loss_2Dto3D = 1 - metric(rgb_feat_pred[~xyz_mask], rgb_patch[~xyz_mask]).mean()cos_sim_3Dto2D, cos_sim_2Dto3D = 1 - loss_3Dto2D.cpu(), 1 - loss_2Dto3D.cpu()xxxxxxxxxx# Inference.for (rgb, pc, depth), gt, label, rgb_path in tqdm(test_loader): rgb_patch, xyz_patch = feature_extractor.get_features_maps(rgb, pc) rgb_feat_pred = CFM_3Dto2D(xyz_patch) xyz_feat_pred = CFM_2Dto3D(rgb_patch) xyz_mask = (xyz_patch.sum(axis = -1) == 0) # Mask only the feature vectors that are 0 everywhere. ## 1. 3D Cosine Similarity. cos_3d = (xyz_feat_pred - xyz_patch).pow(2).sum(1).sqrt() cos_3d[xyz_mask] = 0. cos_3d = cos_3d.reshape(224,224)
## 2. 2D Cosine Similarity. cos_2d = (rgb_feat_pred - rgb_patch).pow(2).sum(1).sqrt() cos_2d[xyz_mask] = 0. cos_2d = cos_2d.reshape(224,224)
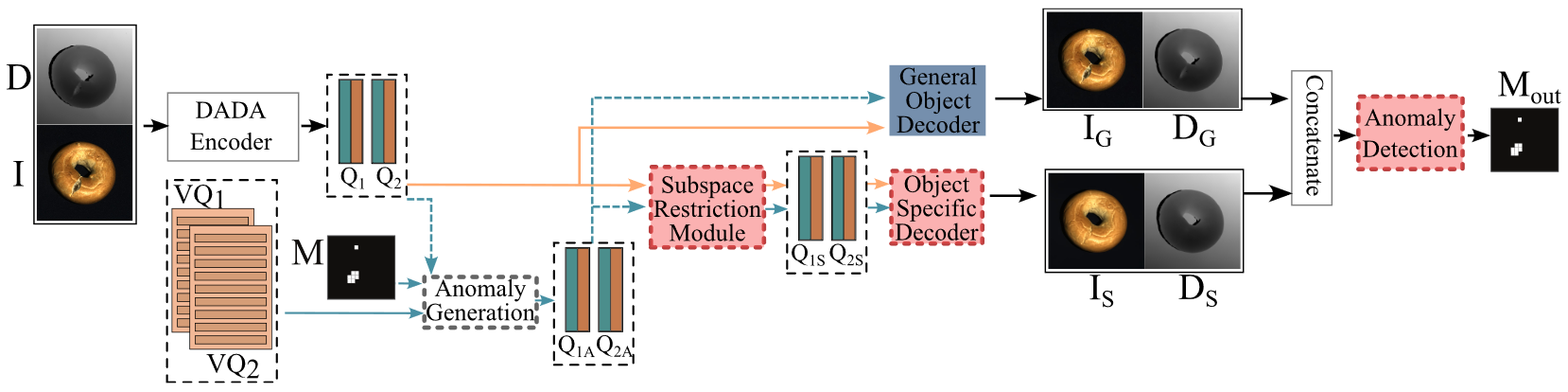
## 3. Combined Cosine Similarity. cos_comb = (cos_2d * cos_3d) cos_comb.reshape(-1)[xyz_mask] = 0. cos_comb = cos_comb.reshape(1, 1, 224, 224) # Repeated box filters to approximate a Gaussian blur.3D Dual Subspace Reprojection (3DSR)
论文:Cheating Depth: Enhancing 3D Surface Anomaly Detection via Depth Simulation (WACV 2024)
xxxxxxxxxx# Depth-Aware Discrete Autoencoder. class DiscreteLatentModel(nn.Module): def __init__(self, ...): ... def forward(self, x): # Encoder Hi enc_b = self._encoder_b(x) # 3 × nn.Conv2d + ResidualStack
# Encoder Lo -- F_Lo enc_t = self._encoder_t(enc_b) # 2 × nn.Conv2d + ResidualStack zt = self._pre_vq_conv_top(enc_t) # nn.Conv2d
# Quantize F_Lo with K_Lo loss_t, quantized_t, perplexity_t, encodings_t = self._vq_vae_top(zt) # nn.Embedding # Upsample Q_Lo up_quantized_t = self.upsample_t(quantized_t)
# Concatenate and transform the output of Encoder_Hi and upsampled Q_lo -- F_Hi feat = torch.cat((enc_b, up_quantized_t), dim=1) zb = self._pre_vq_conv_bot(feat) # nn.Conv2d
# Quantize F_Hi with K_Hi loss_b, quantized_b, perplexity_b, encodings_b = self._vq_vae_bot(zb) # nn.Embedding
# Concatenate Q_Hi and Q_Lo and input it into the General appearance decoder quant_join = torch.cat((up_quantized_t, quantized_b), dim=1) recon_fin = self._decoder_b(quant_join) # nn.Conv2d + ResidualStack + 2 × nn.ConvTranspose2d
# return loss_b, loss_t, recon_fin, encodings_t, encodings_b, quantized_t, quantized_b return loss_b, loss_t, recon_fin, quantized_t, quantized_bxxxxxxxxxx# Depth-Aware Discrete Autoencoder (DADA) Training. model = DiscreteLatentModel()for sample_batched in dataloader: depth_image = sample_batched["image"].cuda() rgb_image = sample_batched["rgb_image"].cuda() model_in = torch.cat((depth_image, rgb_image), dim=1).float()
loss_b, loss_t, recon_out, _, _ = model(model_in) loss_vq = loss_b + loss_t # L2 loss when input (depth) image only. recon_loss = torch.mean((model_in - recon_out)**2) # L1 loss when input (rgb + depth) images only(may work better and lead to improved reconstructions). recon_loss = torch.mean(torch.abs(model_in - recon_out)) recon_loss = recon_loss + loss_vq loss = recon_lossxxxxxxxxxx# Dual Subspace Reprojection (DSR) Training.## 1. Model Instantiation.model = DiscreteLatentModel()
## 2. Modules using the codebooks K_hi and K_lo for feature quantization.embedder_hi = model._vq_vae_botembedder_lo = model._vq_vae_top
## 3. Define the subspace restriction modules - Encoder decoder networks.sub_res_model_lo = SubspaceRestrictionModule(embedding_size=embedding_dim)sub_res_model_hi = SubspaceRestrictionModule(embedding_size=embedding_dim)
# 4. Define the anomaly detection module - UNet-based network.decoder_seg = AnomalyDetectionModule(in_channels=2, base_width=32) # U-Net
## 5. Image reconstruction network reconstructs the image from discrete features.### It is trained for a specific object.model_decode = ImageReconstructionNetwork()
## 6. Training.for i_batch, (depth_image, rgb_image, anomaly_mask) in enumerate(dataloader): in_image = torch.cat((depth_image, rgb_image),dim=1)
anomaly_strength_lo = (torch.rand(in_image.shape[0]) * 0.90 + 0.10).cuda() anomaly_strength_hi = (torch.rand(in_image.shape[0]) * 0.90 + 0.10).cuda() ### (1) Extract features from the discrete model. enc_b, enc_t = model._encoder_b(in_image), model._encoder_t(enc_b) zt = model._pre_vq_conv_top(enc_t)
### (2) Quantize the extracted features. _, quantized_t, _, _ = embedder_lo(zt)
### (3) Quantize the features augmented with anomalies. '''Generate feature-based anomalies on low-level feature.''' anomaly_embedding_lo = generate_fake_anomalies_joined(zt, quantized_t, embedder_lo, anomaly_strength_lo) '''Upsample the quantized features augmented with anomalies''' zb = model._pre_vq_conv_bot(torch.cat((enc_b, model.upsample_t(anomaly_embedding_lo)), dim=1)) '''Upsample the extracted quantized features''' zb_real = model._pre_vq_conv_bot(torch.cat((enc_b, model.upsample_t(quantized_t)), dim=1)) '''Quantize the upsampled features - F_hi''' _, quantized_b, _, _ = embedder_hi(zb) _, quantized_b_real, _, _ = embedder_hi(zb_real)
### (4) Generate feature-based anomalies on F_hi. '''Generate feature-based anomalies on low-level feature augmented with anomalies.''' anomaly_embedding_hi = generate_fake_anomalies_joined(zb, quantized_b, embedder_hi, anomaly_strength_hi) '''Generate feature-based anomalies on low-level feature.''' anomaly_embedding_hi_usebot = generate_fake_anomalies_joined(zb_real, quantized_b_real, embedder_hi, anomaly_strength_hi) use_both = torch.randint(0, 2,(in_image.shape[0],1,1,1)) use_lo = torch.randint(0, 2,(in_image.shape[0],1,1,1)) use_hi = (1 - use_lo) anomaly_embedding_lo_usebot = quantized_t anomaly_embedding_hi_usetop = quantized_b_real anomaly_embedding_lo_usetop = anomaly_embedding_lo anomaly_embedding_hi_not_both = (1 - use_lo) * anomaly_embedding_hi_usebot + use_lo * anomaly_embedding_hi_usetop anomaly_embedding_lo_not_both = (1 - use_lo) * anomaly_embedding_lo_usebot + use_lo * anomaly_embedding_lo_usetop anomaly_embedding_hi = (anomaly_embedding_hi * use_both + anomaly_embedding_hi_not_both * (1.0 - use_both)) anomaly_embedding_lo = (anomaly_embedding_lo * use_both + anomaly_embedding_lo_not_both * (1.0 - use_both))
### (5) Restore the features to normality with the Subspace restriction modules. recon_feat_hi, recon_embeddings_hi, _ = sub_res_model_hi(anomaly_embedding_hi, embedder_hi) recon_feat_lo, recon_embeddings_lo, _ = sub_res_model_lo(anomaly_embedding_lo, embedder_lo)
### (6) Reconstruct the image from the anomalous features with the general appearance decoder. up_quantized_anomaly_t = model.upsample_t(anomaly_embedding_lo) quant_join_anomaly = torch.cat((up_quantized_anomaly_t, anomaly_embedding_hi), dim=1) recon_image_general = model._decoder_b(quant_join_anomaly)
### (7) Reconstruct the image with the object-specific image reconstruction module. up_quantized_recon_t = model.upsample_t(recon_embeddings_lo) quant_join = torch.cat((up_quantized_recon_t, recon_embeddings_hi), dim=1) recon_image_recon = model_decode(quant_join)
out_mask = decoder_seg(recon_image_recon,recon_image_general) out_mask_sm = torch.softmax(out_mask, dim=1)
### (8) Calculate losses loss_feat_hi = torch.nn.functional.mse_loss(recon_feat_hi, quantized_b_real.detach()) loss_feat_lo = torch.nn.functional.mse_loss(recon_feat_lo, quantized_t.detach()) loss_l2_recon_img = torch.nn.functional.mse_loss(in_image, recon_image_recon) total_recon_loss = loss_feat_lo + loss_feat_hi + loss_l2_recon_img*10 '''Resize the ground truth anomaly map to closely match the augmented features''' down_ratio_x_hi = int(anomaly_mask.shape[3] / quantized_b.shape[3]) anomaly_mask_hi = max_pool2d(anomaly_mask, (down_ratio_x_hi, down_ratio_x_hi)) down_ratio_x_lo = int(anomaly_mask.shape[3] / quantized_t.shape[3]) anomaly_mask_lo = max_pool2d(anomaly_mask, (down_ratio_x_lo, down_ratio_x_lo)) anomaly_mask = anomaly_mask_lo * use_both + (anomaly_mask_lo * use_lo + anomaly_mask_hi * use_hi) * (1.0 - use_both) '''Calculate the segmentation loss (# L1 may improve results in some cases)''' segment_loss = loss_focal(out_mask_sm, anomaly_mask) l1_mask_loss = torch.mean(torch.abs(out_mask_sm - torch.cat((1.0 - anomaly_mask, anomaly_mask), dim=1))) segment_loss = segment_loss + l1_mask_lossxxxxxxxxxx# Dual Subspace Reprojection (DSR) Inference.## 1. Model Instantiation.'''Import subspace restriction modules - Encoder decoder networks.'''sub_res_model_lo = SubspaceRestrictionModule() # Load checkpoints then.sub_res_model_hi = SubspaceRestrictionModule() # Load checkpoints then.'''Import anomaly detection module - UNet-based network'''decoder_seg = AnomalyDetectionModule() # Load checkpoints then.'''Import image reconstruction network'''model_decode = ImageReconstructionNetwork() # Load checkpoints then.
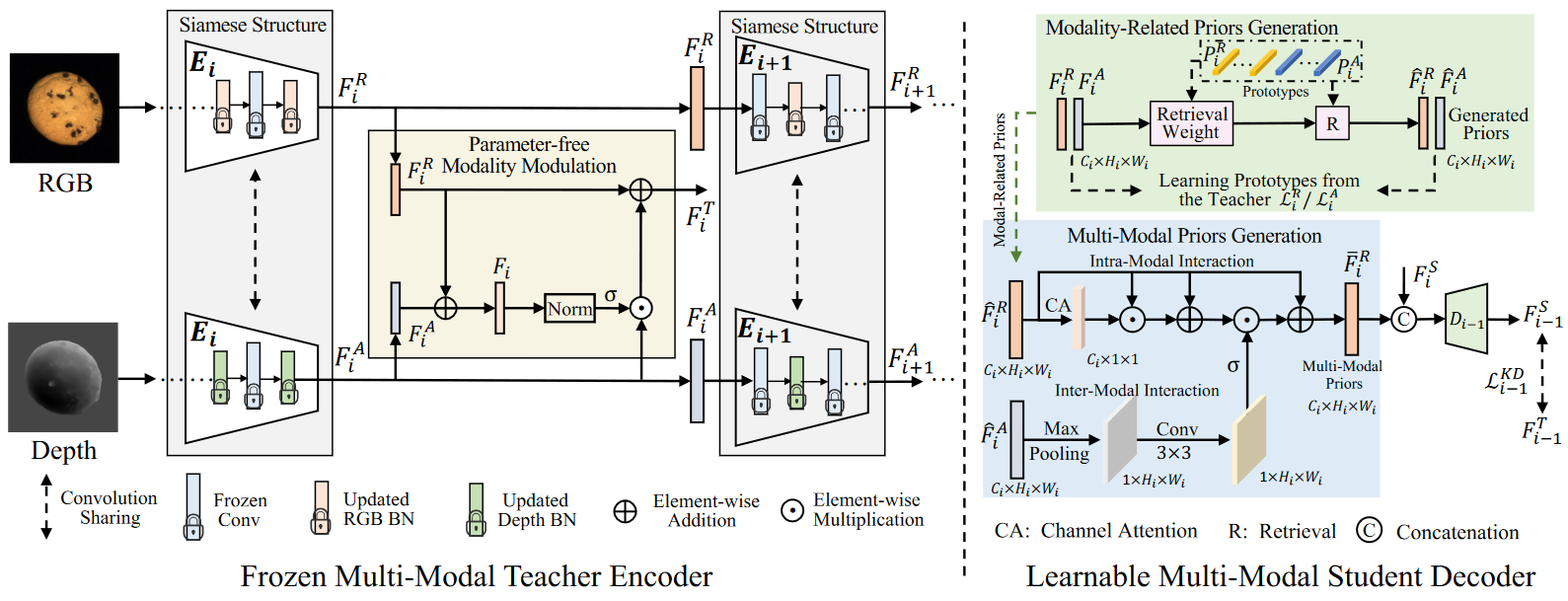
## 2. Inference.for i_batch, (depth_image, rgb_image) in enumerate(dataloader): in_image = torch.cat((depth_image, rgb_image), dim=1) ### (1) Extract features from the discrete model. _, _, recon_out, embeddings_lo, embeddings_hi = model(in_image) recon_image_general = recon_out _, recon_embeddings_hi, _ = sub_res_model_hi(embeddings_hi, embedder_hi) _, recon_embeddings_lo, _ = sub_res_model_lo(embeddings_lo, embedder_lo) ### (2) Reconstruct the image with the object-specific image reconstruction module up_quantized_recon_t = model.upsample_t(recon_embeddings_lo) quant_join = torch.cat((up_quantized_recon_t, recon_embeddings_hi), dim=1) recon_image_recon = model_decode(quant_join) ### (3) Generate the anomaly segmentation map out_mask = decoder_seg(recon_image_recon, recon_image_general) out_mask_sm = softmax(out_mask, dim=1) out_mask_averaged = avg_pool2d(out_mask_sm[:, 1:, :, :], 11, stride=1, padding=11 // 2)Multi-Modal Reverse Distillation (MMRD)
论文:Rethinking Reverse Distillation for Multi-Modal Anomaly Detection (AAAI 2024)
Dual-modality Anomaly Synthesis (DAS3D)
论文:DAS3D: Dual-modality Anomaly Synthesis for 3D Anomaly Detection (arXiv 2024)
检测算法(基于 Text + RGB + Point Cloud)
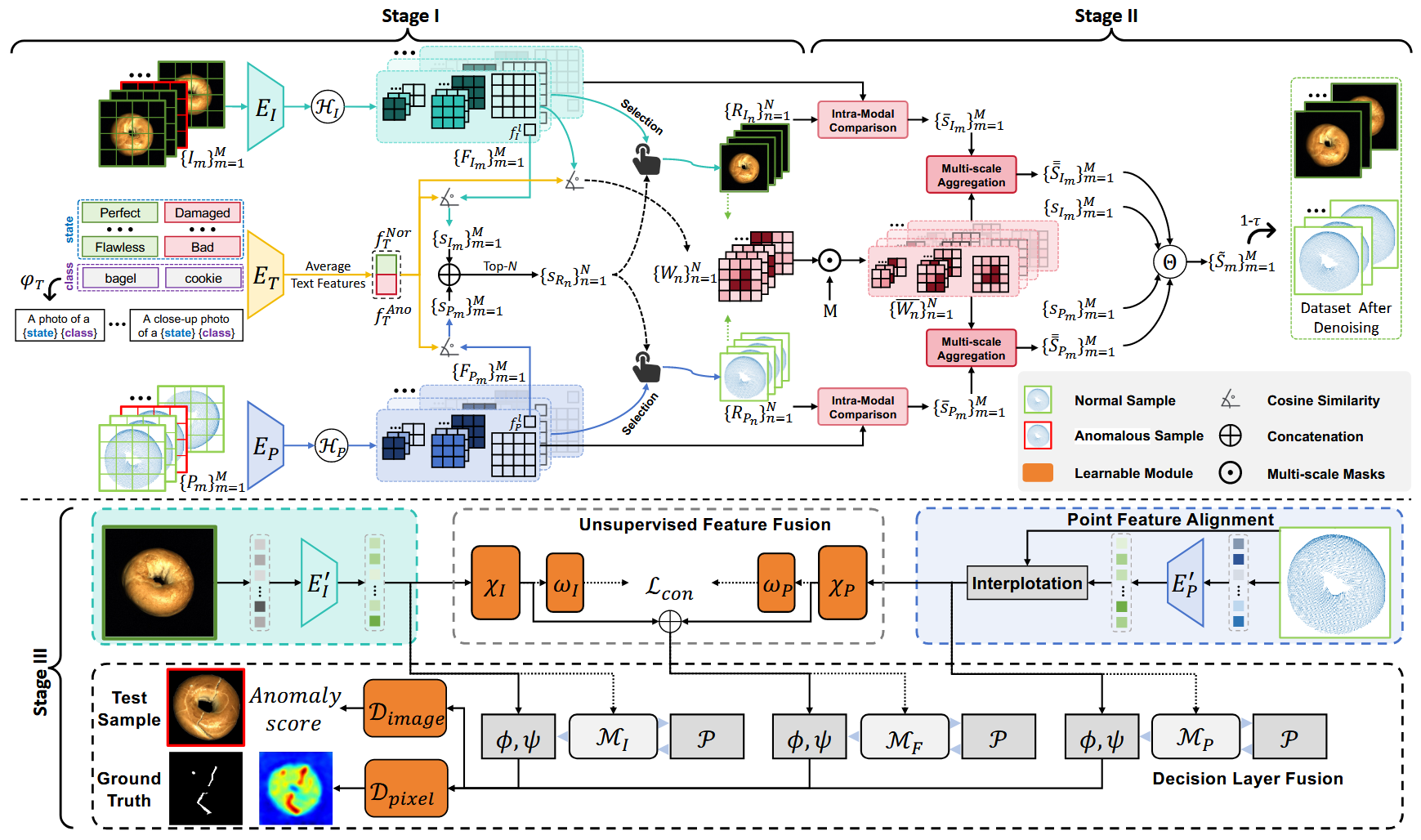
Noisy-Resistant Multi-3D-Memory (M3DM-NR)
论文:M3DM-NR: RGB-3D Noisy-Resistant Industrial Anomaly Detection via Multimodal Denoising (arXiv 2024)
结果现状
Image-AUROC
| Method | Pubication | Bagel | Cable Gland | Carrot | Cookie | Dowel | Foam | Peach | Potato | Rope | Tire | Mean |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DepthGAN [1] | VISIGRAPP'22 | 0.538 | 0.372 | 0.580 | 0.603 | 0.430 | 0.534 | 0.642 | 0.601 | 0.443 | 0.577 | 0.532 |
| DepthAE [1] | VISIGRAPP'22 | 0.648 | 0.502 | 0.650 | 0.488 | 0.805 | 0.522 | 0.712 | 0.529 | 0.540 | 0.552 | 0.595 |
| DepthVM [1] | VISIGRAPP'22 | 0.513 | 0.551 | 0.477 | 0.581 | 0.617 | 0.716 | 0.450 | 0.421 | 0.598 | 0.623 | 0.555 |
| VoxelGAN [1] | VISIGRAPP'22 | 0.680 | 0.324 | 0.565 | 0.399 | 0.497 | 0.482 | 0.566 | 0.579 | 0.601 | 0.482 | 0.518 |
| VoxelAE [1] | VISIGRAPP'22 | 0.510 | 0.540 | 0.384 | 0.693 | 0.446 | 0.632 | 0.550 | 0.494 | 0.721 | 0.413 | 0.538 |
| VoxelVM [1] | VISIGRAPP'22 | 0.553 | 0.772 | 0.484 | 0.701 | 0.751 | 0.578 | 0.480 | 0.466 | 0.689 | 0.611 | 0.609 |
| 3D-ST [2] | WACV'23 | 0.950 | 0.483 | 0.986 | 0.921 | 0.905 | 0.632 | 0.945 | 0.988 | 0.976 | 0.542 | 0.833 |
| BTF [3] | CVPR'23 | 0.918 | 0.748 | 0.967 | 0.883 | 0.932 | 0.582 | 0.896 | 0.912 | 0.921 | 0.886 | 0.865 |
| EasyNet [4] | MM'23 | 0.991 | 0.998 | 0.918 | 0.968 | 0.945 | 0.945 | 0.905 | 0.807 | 0.994 | 0.793 | 0.926 |
| AST [5] | WACV'23 | 0.983 | 0.873 | 0.976 | 0.971 | 0.932 | 0.885 | 0.974 | 0.981 | 1.000 | 0.797 | 0.937 |
| CMDIAD [6] | arXiv'24 | 0.992 | 0.893 | 0.977 | 0.960 | 0.953 | 0.883 | 0.950 | 0.937 | 0.943 | 0.893 | 0.938 |
| M3DM [7] | CVPR'23 | 0.994 | 0.909 | 0.972 | 0.976 | 0.960 | 0.942 | 0.973 | 0.899 | 0.972 | 0.850 | 0.945 |
| M3DM-NR [8] | arXiv'24 | 0.993 | 0.911 | 0.977 | 0.976 | 0.960 | 0.922 | 0.973 | 0.899 | 0.955 | 0.882 | 0.945 |
| Shape-Guided [9] | ICML'23 | 0.986 | 0.894 | 0.983 | 0.991 | 0.976 | 0.857 | 0.990 | 0.965 | 0.960 | 0.869 | 0.947 |
| MMRD [10] | AAAI'24 | 0.999 | 0.943 | 0.964 | 0.943 | 0.992 | 0.912 | 0.949 | 0.901 | 0.994 | 0.901 | 0.950 |
| CPMF [11] | PR'24 | 0.983 | 0.889 | 0.989 | 0.991 | 0.958 | 0.802 | 0.988 | 0.959 | 0.979 | 0.969 | 0.951 |
| CFM [12] | CVPR'24 | 0.994 | 0.888 | 0.984 | 0.993 | 0.980 | 0.888 | 0.941 | 0.943 | 0.980 | 0.953 | 0.954 |
| LSFA [13] | arXiv'24 | 1.000 | 0.939 | 0.982 | 0.989 | 0.961 | 0.951 | 0.983 | 0.962 | 0.989 | 0.951 | 0.971 |
| 3DSR [14] | WACV'24 | 0.981 | 0.867 | 0.996 | 0.981 | 1.000 | 0.994 | 0.986 | 0.978 | 1.000 | 0.995 | 0.978 |
| DAS3D [15] | arXiv'24 | 0.997 | 0.973 | 0.999 | 0.992 | 0.970 | 0.995 | 0.962 | 0.954 | 0.998 | 0.977 | 0.982 |
Pixel-AUROC
| Method | Pubication | Bagel | Cable Gland | Carrot | Cookie | Dowel | Foam | Peach | Potato | Rope | Tire | Mean |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AST [5] | WACV'23 | - | - | - | - | - | - | - | - | - | - | 0.976 |
| CMDIAD [6] | arXiv'24 | 0.995 | 0.993 | 0.996 | 0.976 | 0.984 | 0.988 | 0.996 | 0.995 | 0.997 | 0.996 | 0.992 |
| BTF [3] | CVPR'23 | - | - | - | - | - | - | - | - | - | - | 0.992 |
| M3DM [7] | CVPR'23 | 0.995 | 0.993 | 0.997 | 0.979 | 0.985 | 0.989 | 0.996 | 0.994 | 0.997 | 0.996 | 0.992 |
| M3DM-NR [8] | arXiv'24 | 0.996 | 0.993 | 0.997 | 0.979 | 0.985 | 0.989 | 0.996 | 0.995 | 0.997 | 0.996 | 0.992 |
| CFM [12] | CVPR'24 | - | - | - | - | - | - | - | - | - | - | 0.993 |
| DAS3D [15] | arXiv'24 | - | - | - | - | - | - | - | - | - | - | 0.993 |
| 3DSR [14] | WACV'24 | - | - | - | - | - | - | - | - | - | - | 0.995 |
参考文献
[1] Bergmann P, Jin X, Sattlegger D, et al. The mvtec 3d-ad dataset for unsupervised 3d anomaly detection and localization[J]. arXiv preprint arXiv:2112.09045, 2021.
[2] Bergmann P, Sattlegger D. Anomaly detection in 3d point clouds using deep geometric descriptors[C]//Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2023: 2613-2623.
[3] Horwitz E, Hoshen Y. Back to the feature: classical 3d features are (almost) all you need for 3d anomaly detection[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. 2023: 2968-2977.
[4] Chen R, Xie G, Liu J, et al. Easynet: An easy network for 3d industrial anomaly detection[C]//Proceedings of the 31st ACM International Conference on Multimedia. 2023: 7038-7046.
[5] Rudolph M, Wehrbein T, Rosenhahn B, et al. Asymmetric student-teacher networks for industrial anomaly detection[C]//Proceedings of the IEEE/CVF winter conference on applications of computer vision. 2023: 2592-2602.
[6] Sui W, Lichau D, Lefèvre J, et al. Incomplete Multimodal Industrial Anomaly Detection via Cross-Modal Distillation[J]. arXiv preprint arXiv:2405.13571, 2024.
[7] Wang Y, Peng J, Zhang J, et al. Multimodal industrial anomaly detection via hybrid fusion[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023: 8032-8041.
[8] Wang C, Zhu H, Peng J, et al. M3DM-NR: RGB-3D Noisy-Resistant Industrial Anomaly Detection via Multimodal Denoising[J]. arXiv preprint arXiv:2406.02263, 2024.
[9] Chu Y M, Liu C, Hsieh T I, et al. Shape-Guided Dual-Memory Learning for 3D Anomaly Detection[C]//International Conference on Machine Learning. PMLR, 2023: 6185-6194.
[10] Gu Z, Zhang J, Liu L, et al. Rethinking Reverse Distillation for Multi-Modal Anomaly Detection[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2024, 38(8): 8445-8453.
[11] Cao Y, Xu X, Shen W. Complementary pseudo multimodal feature for point cloud anomaly detection[J]. Pattern Recognition, 2024, 156: 110761.
[12] Costanzino A, Ramirez P Z, Lisanti G, et al. Multimodal industrial anomaly detection by crossmodal feature mapping[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024: 17234-17243.
[13] Tu Y, Zhang B, Liu L, et al. Self-supervised Feature Adaptation for 3D Industrial Anomaly Detection[J]. arXiv preprint arXiv:2401.03145, 2024.
[14] Zavrtanik V, Kristan M, Skočaj D. Cheating depth: Enhancing 3d surface anomaly detection via depth simulation[C]//Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2024: 2164-2172.
[15] Li K, Dai B, Fu J, et al. DAS3D: Dual-modality Anomaly Synthesis for 3D Anomaly Detection[J]. arXiv preprint arXiv:2410.09821, 2024.