Vision-Language-Action Models
Google 的 DeepMind 团队基于互联网上数据训练视觉-语言模型(VLM),使其能够学习到视觉和语言之间映射关系的知识,在机器人操纵任务上微调
RT-1
论文2022年12月13日上传至 arXiv https://arxiv.org/abs/2212.06817
代码2022年12月10日上传至 Github https://github.com/google-research/robotics_transformer
概述
Robot:用于RT-1 研究的机器人有7个自由度的机械臂、两个手指型夹抓,以及一个移动基座
Dataset:17个月的时间内收集了13个机器人的〜130k 个片段和700多个任务数据
Input / Output:采用图像和自然语言指令,并输出离散的基础和手臂动作,包括:手臂运动的七个维度(x、 y、z、滚动、俯仰、侧滑、夹具打开),基本运动的三个维度(X,Y,侧滑)和一个离散的维度,可以在三种模式之间切换:控制手臂,底座或终止动作。 RT-1执行闭环控制,并以 3 Hz的速度命令操作,直到它产生“终止”动作或达到预设的时间步长限制为止
Architecture:FiLM EfficientNet + TokenLearner + Transformer = 35M parameters
Method:在该数据集的基础之上,基于模仿学习中行为克隆学习范式,把 Transformer 应用机器人的操纵任务上,提出了 RT-1模型
Success:RT-1可以以97%的成功率执行700多种指令,可以推广到新的任务、干扰因素和背景,比下一个最佳基线分别高25%、36%和18%
Limitation:依赖真实机器人数据,强于已知任务,但泛化能力有限
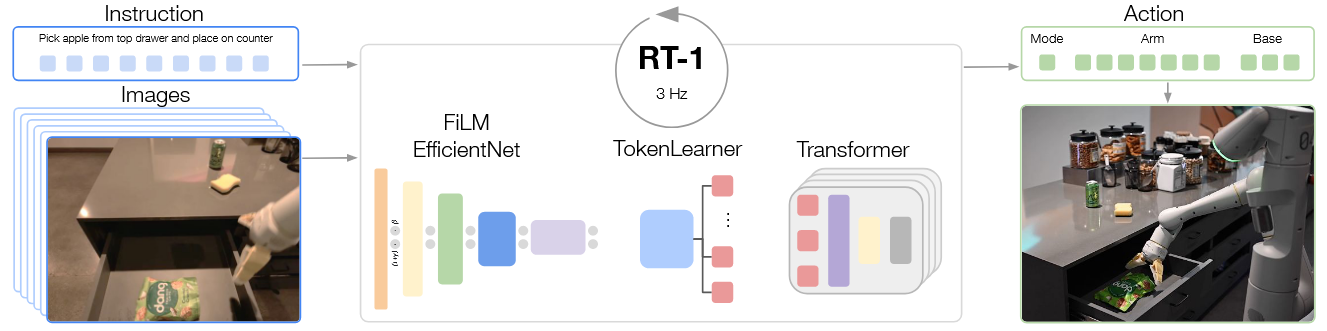
模型架构
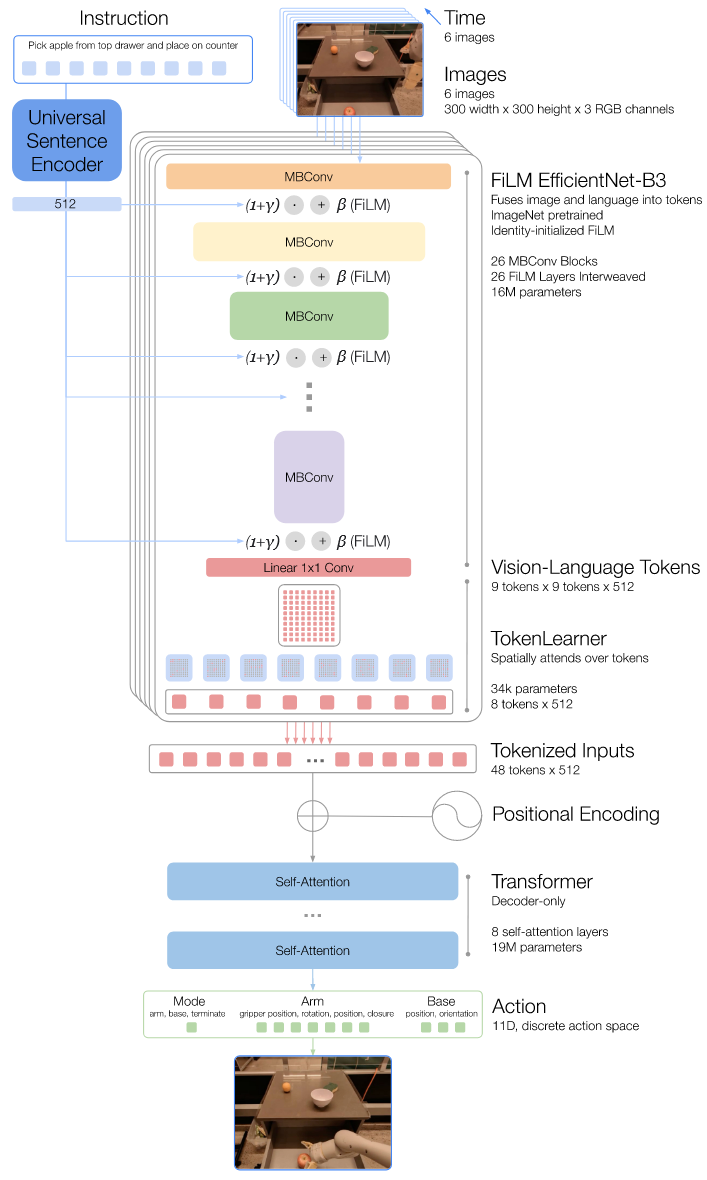 | Instruction and Image Tokenization(16M): 6 幅300×300的图像输入预训练EfficientNet-B3进行tokenize ,利用最终卷积层输出的9×9×512的空间特征图,形成81个tokens TokenLearner: 将81个视觉令牌子采样为8个最终令牌,然后传递给Transformer层 Transformer(19M) 将每个图像的这8个令牌与其他图像连接起来,形成总共48个令牌(添加了位置编码),馈送到RT-1的Transformer骨干中 Action Tokenization RT-1中的每个动作维度都被离散化为256个bins,每个bin在对应变量的边界内均匀分布 Loss 标准分类交叉熵熵和causal masking |
|---|
表现
Generalization:
Seen Tasks:执行 200+ 个指令,成功率达 97%
Unseen Tasks:成功率达76%,比下一最佳 baseline(Gato)高 24%

Robustness:
Distractors(干扰):包含2至4个干扰物对象。在最具挑战性的情况下,场景非常混乱,并包含感兴趣的对象的遮挡

Backgrounds(背景):测试RT-1在具有不同桌面纹理和不同背景的设置上的性能

RT-2
论文2023年07月28日上传至 arXiv https://arxiv.org/abs/2307.15818
CoRL 2023 接收
概述
Method:提出了一个在机器人轨迹数据和互联网级别的视觉语言任务 联合微调 VLM 的学习方式,产生的模型被称为 Vision-Language-Action(VLA)Models。将机器人动作表示为另一种语言,可以将其施加到 Text Tokens 中,并与视觉语言数据集进行训练。在推理过程中,Text Tokens 被 De-Tokenize 为机器人动作,从而实现闭环控制(Close-Loop Control)
Difference from RT-1:RT-1 是利用预训练模型对视觉与语言进行编码,然后再通过解码器输出动作。 RT-2 则是把语言、动作、图片放在一个统一的输出空间,利用 VLMs 产生动作”语言“。
Limitation:机器人能够成功做出的动作已经是预先设计好的,VLM 只是能够帮助机器人选择合适的任务规划
注:Close-Loop Control:将控制系统输出量的一部分或全部,通过一定方法和装置反送回系统的输入端,然后将反馈信息与原输入信息进行比较,再将比较的结果施加于系统进行控制,避免系统偏离预定目标。
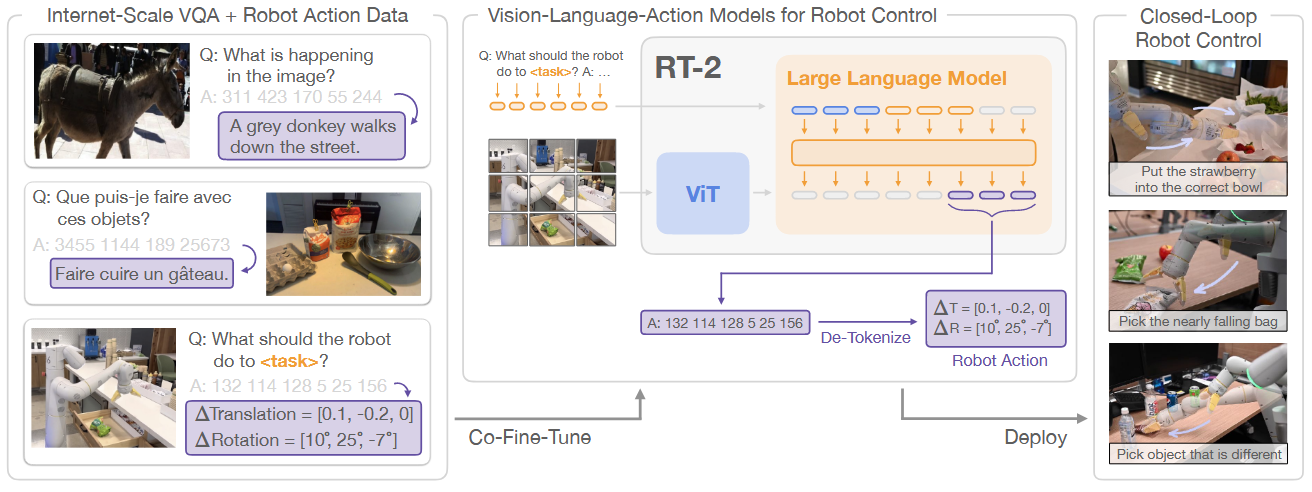
模型架构
Pre-Trained VLMs:采用 Pathways Language and Image (Pali-X) 和 Pathways Language Model Embodied(Palm-E)。单纯的视觉语言模型可以通过网络级的数据训练出来,因为数据量足够大,能够得到足够好的效果
Action Tokenization:同 RT-1 中的离散化编码,每个动作维度都被离散化为256个bins
Action Space:动作空间包括机器人末端执行器的6-DoF位置和旋转位移,以及机器人夹具的延伸水平和用于终止事件的特殊离散命令,该命令应由策略触发以表示成功完成。连续维度(除离散终止命令外的所有维度)被均匀地离散化为256个区间。因此,可以用8个数字来表示一个动作

表现
Generalization:
Seen Tasks:RT-1 和 RT-2 的表现接近
Unseen Tasks:较下一最佳baseline,有约 2倍 的提升
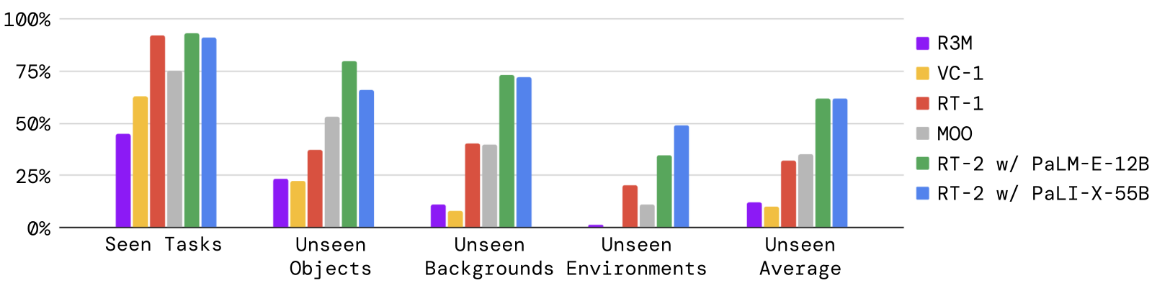
Emergent Capabilities:
例如:将草莓放入正确的碗中 / 拿起即将掉下桌子的袋子
 | 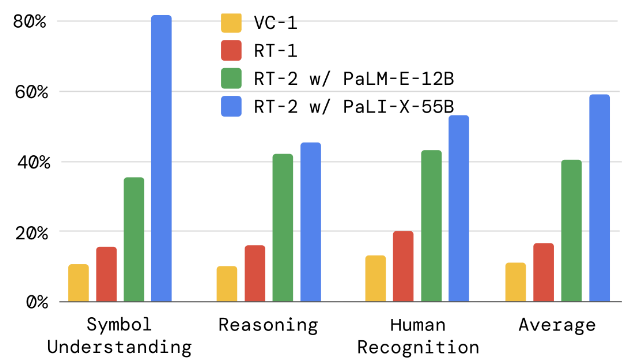 |
|---|
参数量和训练策略的影响:
参数量:RT-2-PaLI-X 的 5B 和 55B 模型
训练策略:1)从头开始训练模型,不使用 VLM 预训练权重;2)仅使用机器人动作数据微调预训练模型;3)联合微调(与视觉语言任务共同微调)
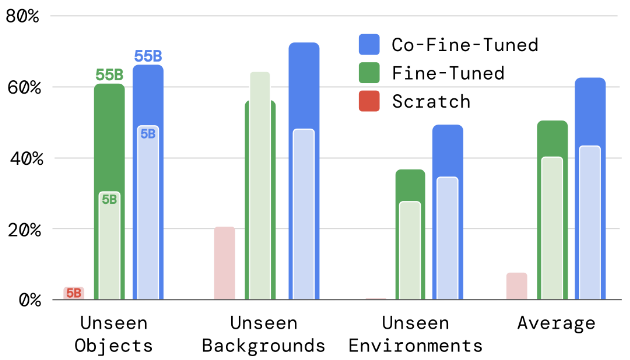
Chain-of-Thought Reasoning:推出具有思维链推理的 RT-2,生成每一步的计划和行动

OpenVLA
论文2024年06月13日上传至 arXiv https://arxiv.org/abs/2406.09246
CoRL 2024 接收
与 RT-2 比较
Smaller Size:OpenVLA 的参数量(7B)仅为 RT-2-X(55B)的大约七分之一
稳健性:
鲁棒性:当机械臂末端受到随机外力干扰时,OpenVLA的轨迹恢复速度比RT-2快 40%
Open-Source:
概述
Robot:在两个不同的机器人平台上进行了“开箱即用”的评估,BridgeData V2中使用的 WidowX 和 RT-2中所使用的平台
Dataset:Open X-Embodiment数据集,这是一个包含超过70个独立机器人数据集的大规模集合,拥有超过200万条机器人轨迹
Input / Output:接收图像观察和语言指令,预测7维的机器人控制动作
Architecture:
视觉编码器:Prismatic-7B VLM,结合了Dino V2 和 SigLIP 的特征,将图像输入映射为一系列"图像patch嵌入"
投影器:将视觉特征映射到语言嵌入空间
LLM:基于70亿参数的Llama 2大型语言模型,处理来自视觉和语言数据的配对或交错输入,并通过预测下一个文本token进行端到端训练
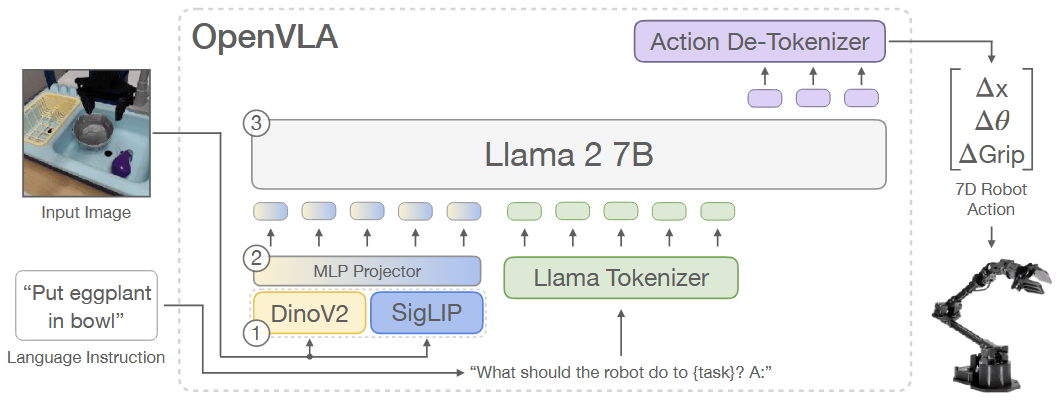
模型架构
Action Tokenization:继承了 RT-1 和 RT-2 中的离散化编码。在其基础上,使用动作数据的1%至99%分位数之间的均匀间隔来设置每个bin的宽度,而不是最小值和最大值(RT-1中提出每个bin在对应变量的边界内均匀分布),这样可以忽略掉可能大幅扩展离散化区间的数据异常值,从而保持较高的离散化精度
关于这一操作的原理和作用,以下回答来自 DeepSeek:
核心原理:使用1%和99%分位数作为区间边界,本质上是基于数据分布的鲁棒性统计。1)排除极端值:过滤掉数据中前1%和后1%的异常值,保留中间98%的主体数据;2)自适应数据分布:分位数直接反映数据的实际密度分布,确保离散化区间覆盖高频动作区域
实际意义和优势:1)增强模型鲁棒性:避免异常值对离散化的干扰;2)提升动作分辨率:在数据密集区域(如中间98%区间)分配更多精细的bins,使模型能区分更细微的动作差异;3)数据效率优化:更高效地利用数据分布信息,避免因极端值导致的无效区间划分;4)泛化能力提升:测试时遇到的动作值更可能落在训练见过的bins中,减少外推误差
总结:OpenVLA的离散化策略本质是以数据驱动代替先验假设,通过分位数排除离群值干扰,聚焦于真实数据分布的核心区域。这不仅提升了动作编码的效率和精度,还增强了模型在实际场景中的鲁棒性和泛化能力,是机器人动作建模中一种更符合真实数据特性的工程优化方案
Training Procedure:采用标准的 Next-token Prediction Objective,即只评估预测的动作token上的交叉熵损失
VLM Backbone:可选的包括 Prismatic,fine-tuning IDEFICS-1,LLAVA,三者在初始 Bridgev2 评估中具有相似的下游性能。最终选择 Prismatic,因其通过融合的siglip-dinov2骨架提高了其空间推理能力(输入图像块分别通过两个编码器,得到的特征向量按通道连接)
Fine-Tuning Vision Encoder:在 VLA 训练期间对视觉编码器进行微调对于良好的 VLA 性能至关重要
表现
Robots:Widow X、Google Robot
Baseline Models:RT-1-X、RT-2-X、Octo
Evaluation Tasks:BridgeDataV2 的 17 个任务/10次演示,Google Robot 的12个任务/5次演示。
Task Categories:视觉(未见背景、干扰物、物体的颜色和外观),运动(未见物体的位置和方向),物理(未见的物体尺寸和形状),语义(未见的目标物体、指令和来自互联网的概念)
与SOTA的对比
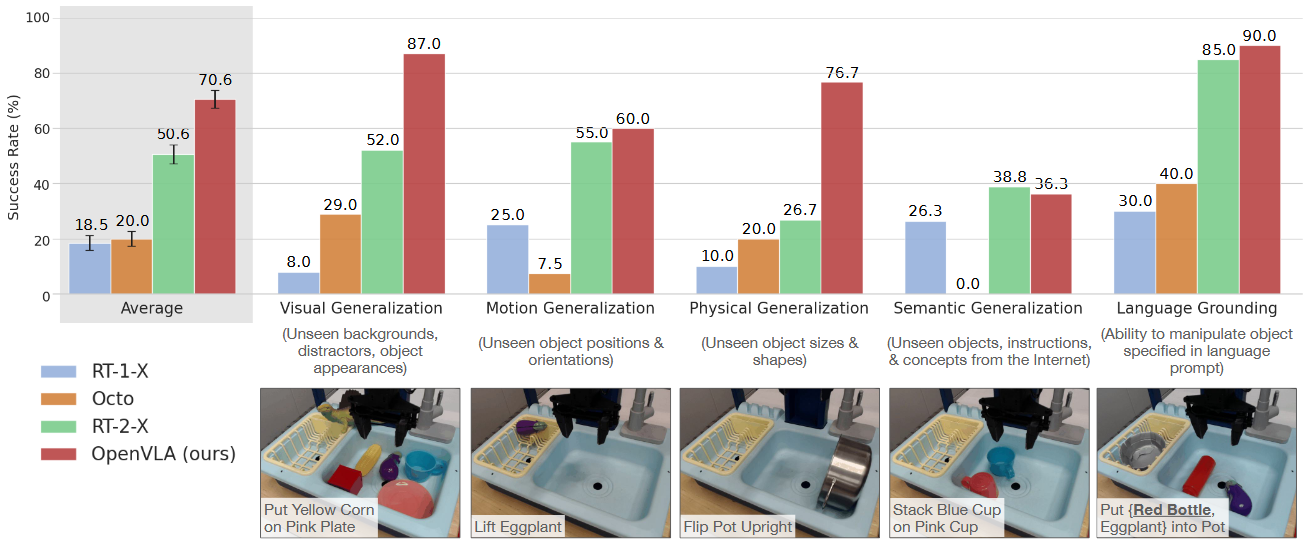 | 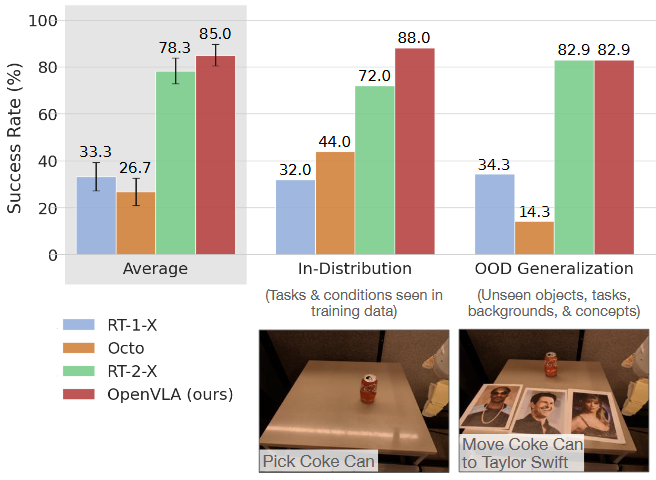 |
|---|---|
| Bridge V2 WidowX Evaluation | Google Robot Evaluation |
对新机器人的适用性
Data-Efficient Adaptation to New Robot Setups:
Franka-Tabletop:固定安装在桌子上的 Franka Emika Panda 7 自由度机器人手臂
Franka-DROID:DROID中的设置(下左图),即安装在可移动的立式桌子上
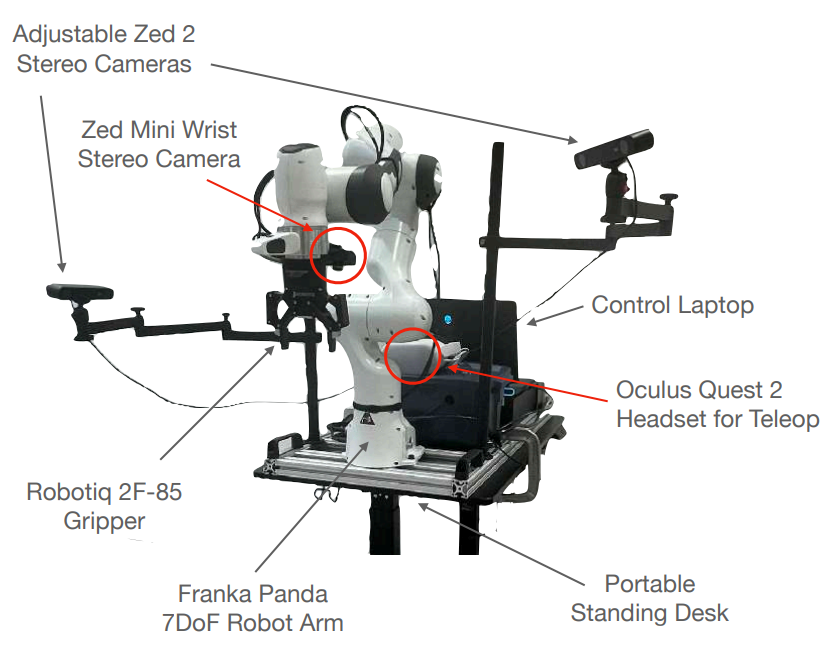 | 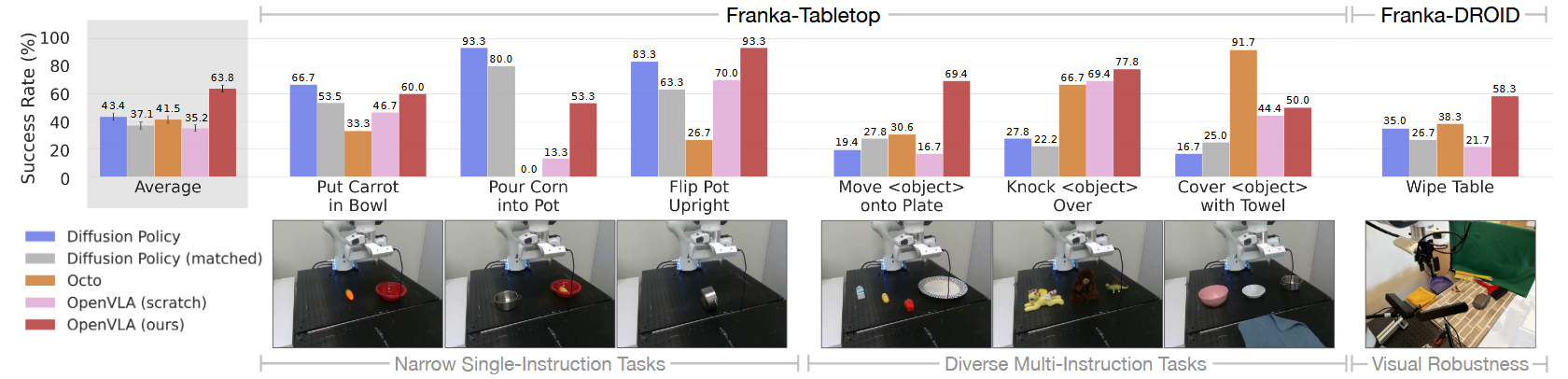 |
|---|---|
| The DROID Robot Platform | Data-Efficient Adaptation Results |
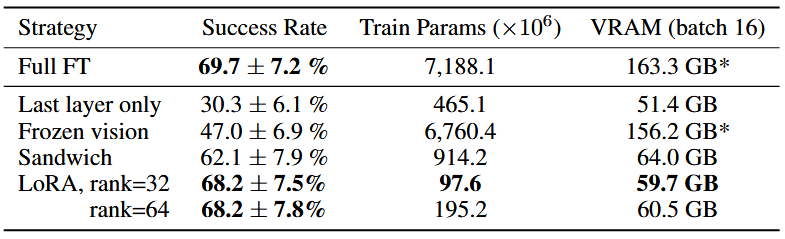
高效微调
Task:Multiple Franka-Tabletop
Fine-tuning Approaches:
Last Layer Only:仅微调 OpenVLA 中 Transformer 骨干网的最后一层和 Token Embedding Matrix
Frozen Vision:冻结视觉编码器,但微调所有其他权重
Sandwich Fine-tuning:解冻了视觉编码器、Token Embedding Matrix 和最后一层
LoRA:使用低秩自适应技术,改变多个秩值 r,应用于模型的所有线性层
结论:借助 LoRA,可以在 10-15 小时内在 单个 A100 GPU 上对新任务微调,与完全微调相比,计算量减少 8 倍
高效推理
结论:4-bit 量化与 bfloat16 推理(默认方法)的性能相匹配,同时将 GPU 内存空间降低一半以上
 | 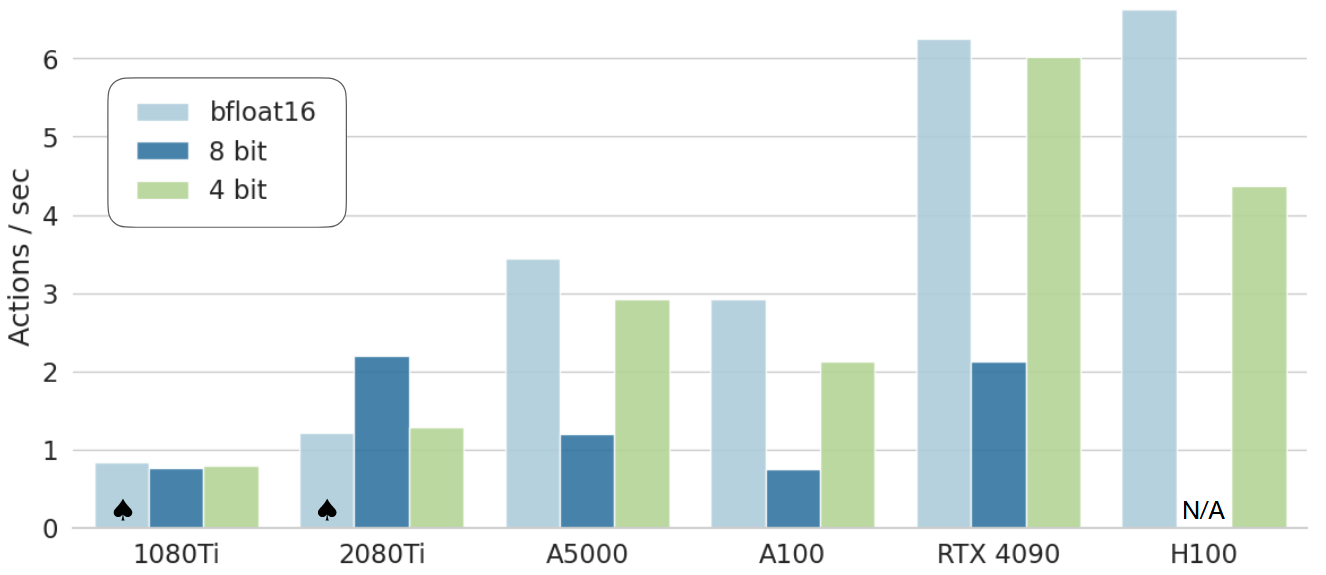 |
|---|---|
| Performance with Quantized Inference | OpenVLA Inference Speed for Various GPUs |