Pytorch使用Visdom可视化(安装和使用教程)
1 Visdom安装
在代码环境下执行以下命令即可安装。
1pip install visdom
2 Visdom可视化训练过程(1) Visdom可视化方法的实现
以下python类可自行实现,这里贴出本人使用的Visdom类和方法。注:以下代码直接拷贝至visualizer.py并与模型训练文件放在同一路径下即可,在需要可视化的文件中调用Visualizer类。
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859606162636465666768697071727374757677787980818283import osimport visdomimport numpy as npimport timeclass Visualizer(object): """ 封装了visdom的基本操作,但是你仍然可以通过`self.vis.function` 或者`se ...
(整理链接)常用网络的Pytorch实现
整理出来方便自用,不用每次都去到处找开源代码。(以下链接中的代码可直接拷贝使用)
CNNsLeNetAlexNetalexnet-pytorch/model.py at d0c1b1c52296ffcbecfbf5b17e1d1685b4ca6744 · dansuh17/alexnet-pytorch (github.com)
VGG系列vision/vgg.py at 6db1569c89094cf23f3bc41f79275c45e9fcb3f3 · pytorch/vision (github.com)
ResNet系列及其衍生系列
ResNet:vision/resnet.py at 6db1569c89094cf23f3bc41f79275c45e9fcb3f3 · pytorch/vision (github.com)
ResNeSt:ResNeSt/resnet.py at 5fe47e93bd7e098d15bc278d8ab4812b82b49414 · zhanghang1989/Re ...
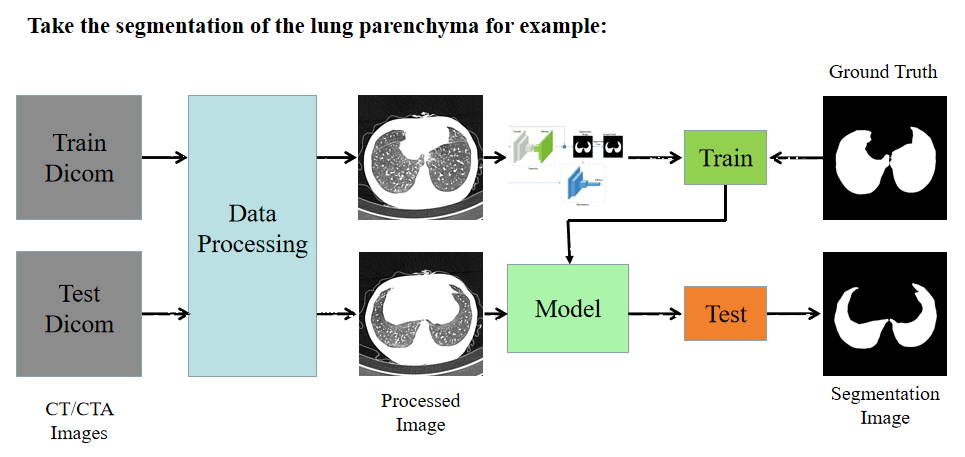
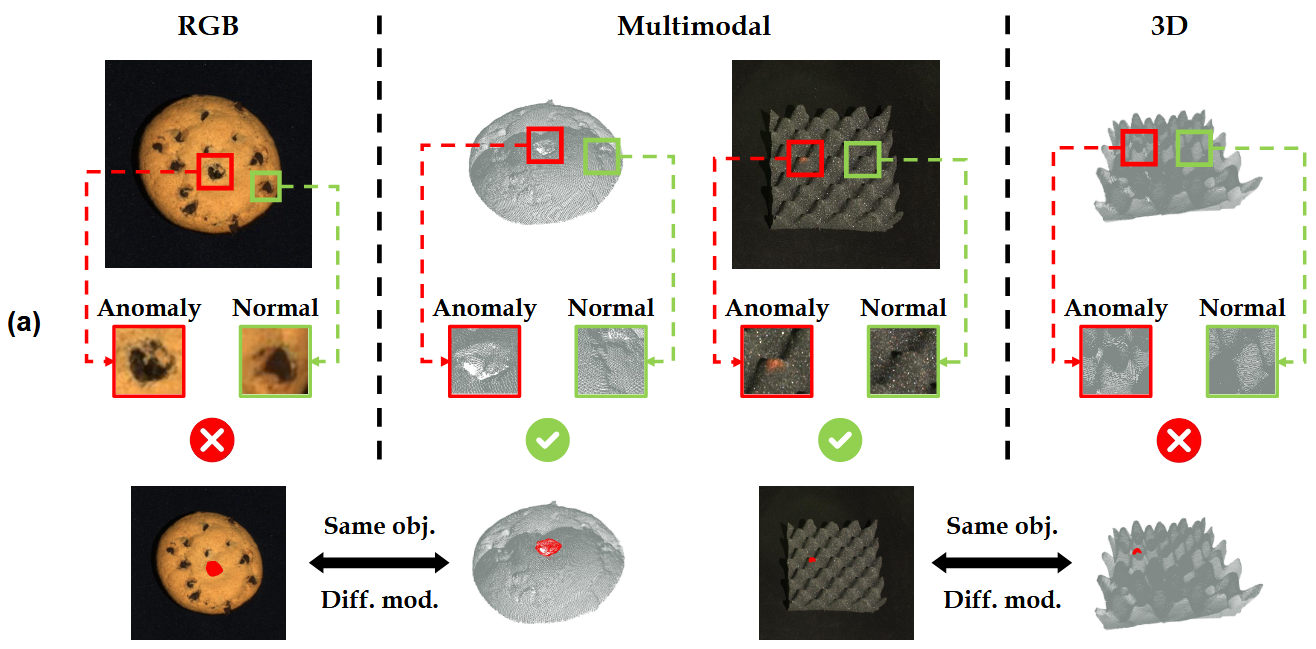
ISICDM_2020挑战赛——肺部组织分割
记录一下沈阳的第四届图像计算与数字医学国际研讨会(The 4th International Symposium on Image Computing and Digital Medicine, ISICDM)挑战赛的竞赛过程。不得不吐槽一下整个过程项目三的主办方的各种延误和低级错误,比如标签给的JPG格式,槽点太多,吐槽不过来。挑战赛官方网址:http://isicdm2020.imagecomputing.org/cn/Challenges.html
一、竞赛背景
我国在工业化发展过程中,由于高度的空气污染、高吸烟率和较差的生产保护条件,导致肺癌、慢阻肺等肺部疾病的发病率一直维持在较高水平,并呈加剧趋势。另外,SARS、 COVID-19等冠状病毒肺炎传染速度快,已被列为威胁全球公众健康的重大传染性疾病。肺部疾病已经成为危害人民健康、社会及经济可持续发展的严重公共卫生问题和社会问题。 当前医学影像已经成为肺部疾病临床检测和诊断、治疗方案规划和术后评估等各个环节的重要依据。近年来,国内外研究者在肺部影像智能辅助诊疗技术方面已取得显著研究进展,在肺部疾病的早期诊断、精准治疗等方面开始 ...

如何评估你的网络模型?
二分类网络的评价指标
Acc, F1, ROC, AUC
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859606162636465666768697071727374757677787980818283848586def Metrics(output, labels): ''' output: <list> labels: <list> ''' test_correct = 0 test_total = 0 predicts = [] prob = [] tp, tn, fp, fn = 0, 0, 0, 0 for outputs in output: index, predicted = torch.max(outputs.data, 1) p ...
经典分割模型的Pytorch实现
FCN-32/16/8/1s(2014)注.Backbone: VGG123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117118119120121122123124125126127128129130131132133134135136137138139140141142143144145146147148149150151152153154155156157158159160161162163164165166167168169170171172173174175176177178179180181182183184185186 ...
经典分类模型的Pytorch实现
以下所有模型输入为224*224的图片,输出层为2个神经元(即可实现二分类问题, 更改输出神经元个数以实现多分类)
LeNet(1998)12345678910111213141516171819202122232425262728293031323334353637import torchimport torch.nn as nnclass LeNet(nn.Module): def __init__(self): super(LeNet,self).__init__() self.conv1 = nn.Sequential( nn.Conv2d(1, 6, 5, 1, 2), nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2) ) self.conv2 = nn.Sequential( nn.Conv2d(6, 16, 5), nn ...

(持续更新中...)认真地做一个“马来人”——深度学习部分
代码常用Pytorch框架下常见问题
Pytorch中Tensor与各种图像格式的相互转化https://blog.csdn.net/qq_36955294/article/details/82888443
Pytorch查看模型细节和参数大小计算(利用torchsummary模块)
123456789101112from torchsummary import summarysummary(model, input_size=(C, H, W))以UNet为例from torchsummary import summarydevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")model = UNet(in_channels=3).to(device)print(model) # 打印整个模型框架parameters = filter( ...
实验室集群环境配置(包括Anaconda环境搭建、Pytorch框架的安装和Jupyter Notebook的配置)
Anaconda环境搭建1 复制压缩包12home/xx cp Anaconda3-5.2.0-Linux-x86_64.sh home/xx(也可直接手动复制粘贴文件)
2 安装1bash Anaconda3-5.2.0-Linux-x86_64.sh
3 添加到到PATH12source ~/.bashrcvi ~/.bashrc(查看PATH)
Pytorch框架和虚拟环境安装(在Anaconda Base下)1source activate base
1 查看CUDA版本1nvcc -V
2 官网pytorch.org查看pytorch安装指令根据所在结点的CUDA版本,安装对应支持的pytorch版本,直接拷贝如下代码即可安装。
12345# CUDA 9.0conda install pytorch==1.1.0 torchvision==0.3.0 cudatoolkit=9.0 -c pytorch# CUDA 11.0+pip install torch==1.8.0+cu111 torchvision==0.9.0+cu111 torchaudio==0 ...
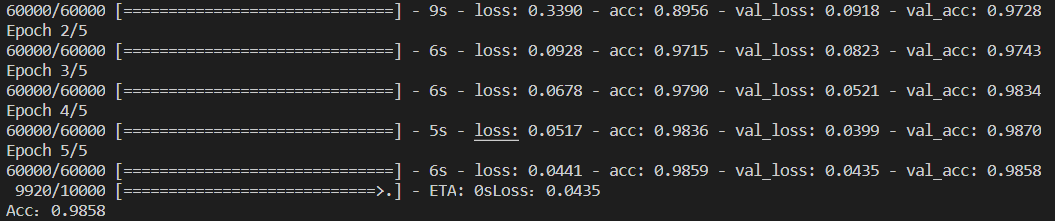
深度学习算法中的Hello-World:用LeNet模型实现手写数字识别
一、Mnist数据集介绍数据集的内容:包含0-9的手写数字数据集的数量:60000个训练集/10000个测试集数据集的格式:28*28数据集通道数:灰度图(单通道通道)
二、LeNet七层模型1、C1卷积层:6个卷积核,大小为5*5,激活函数ReLu1model.add(Conv2D(6, kernel_size = (5,5), activation = 'relu', input_shape = (28,28,1)))
2、S2池化层:最大池化1model.add(MaxPooling2D(pool_size = (2,2)))
3、C3卷积层:16个卷积核,大小为5*5,激活函数ReLu1model.add(Conv2D(16, kernel_size = (5,5), activation = 'relu'))
4、S4池化层:最大池化1model.add(MaxPooling2D(pool_size = (2,2)))
5、C5全连接层:参数扁平化,在LeNet5称之为卷积层,实际上这一层是一维向量,和全连接层一样12 ...

网球相关
球拍(球拍参数查询)
空拍重量
穿线重量
平衡点X pts HL,HL前面的数值X越大其挥重越低,而数值越小其挥重越大。X pts HH,数值越大挥重越大,数值越小挥重越小。
拍面尺寸
硬度球拍被击中后弯曲的程度,用“RA”评级来衡量。比较硬的球拍能给球带来更多的能量,但对手臂的打击更大,振动更大,与比较灵活的球拍相比,感觉和控制力更弱。
挥重拍子挥起来的重量有多大,而挥重的大小则取决于拍子的平衡点。挥重更大的拍子更难去挥动,灵活性也会变差,但是其击球力道会更强,而挥重低的拍子灵活性更好,挥拍速度更快,但是球质会稍差一些。挥重低的拍子也可以通过增加拍子自身更大的重量来弥补。
线床
球拍长度
拍框厚度三个数字,第一个数字代表的是拍头部分拍框的厚度,而第二个数字代表的是拍子甜区左右两侧(3点 & 9点)拍框的厚度,最后一个数字代表的三角区(拍喉)的厚度。更厚的拍框拥有更好的避震和力量,而更薄的拍框拥有更好的手感反馈和控制。
球拍线(球线测评网站)(注意事项)剪线顺序:从下往上竖直剪至甜点处,再向左右两侧横剪,最后竖直剪至拍头,最大限度地保护拍框。
球线类型
硬线(聚酯线)弹力稍差 ...
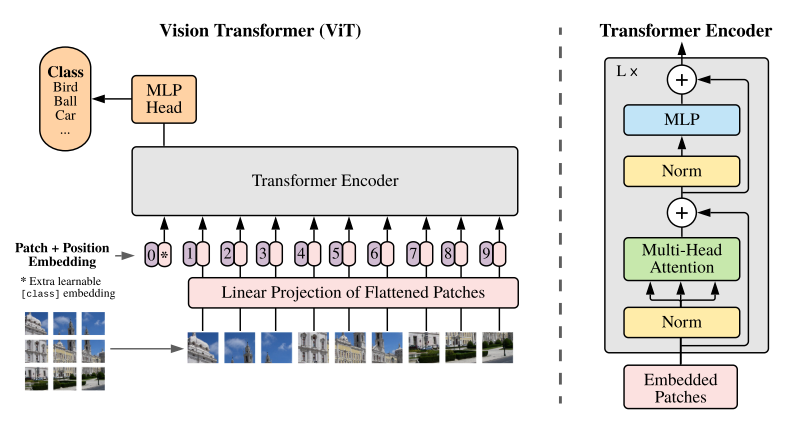
转载:Awesome Visual-Transformer
转载自:[Awesome Visual-Transformer]Collect some Transformer with Computer-Vision (CV) papers.
Awesome Visual-TransformerPapersTransformer original paper
Attention is All You Need (NIPS 2017)
综述
Transformers in Vision: A Survey [paper] - 2021.02.22
A Survey on Visual Transformer [paper] - 2020.1.30
A Survey of Transformers [paper] - 2020.6.09
arXiv papers
[CrossFormer] CrossFormer: A Versatile Vision Transformer Based on Cross-scale Attention [paper] [code]
[Styleformer] Styleformer: Tran ...
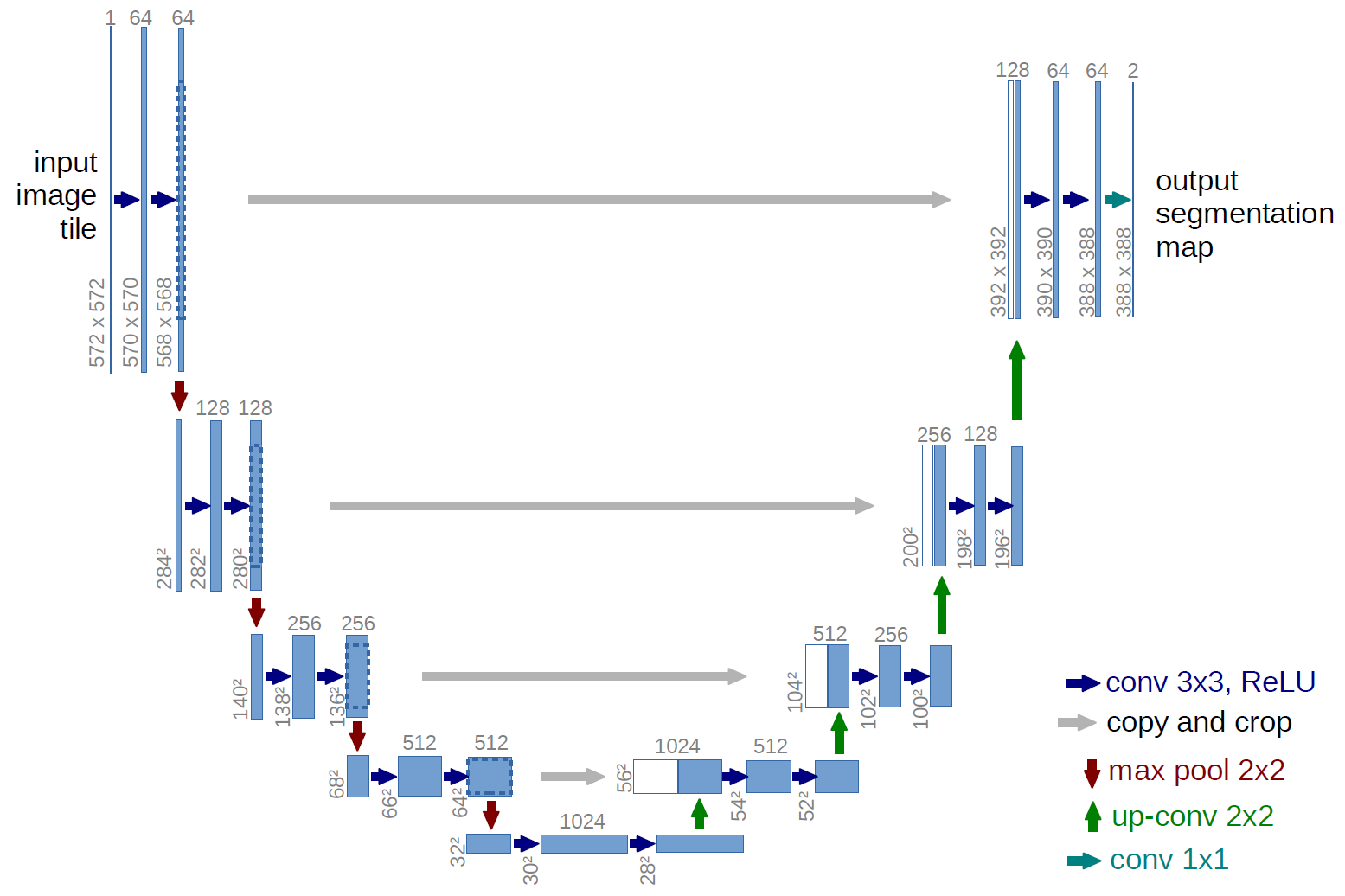
U-Net系列文献综述
一、U-NetContribution
更规整的网络结构
通过将编码器的每层结果拼接到译码器中得到更好的结果
1、Architecture
二、3D U-NetArchitecture
3、Tricks
两种分割方式(1)半自动分割半自动分割网络允许用户输入几个注释的2维切片,来得到整个三维体的分割。在半自动分割方法中,使用了IoU指标作为精度度量,得出结论3D U-Net能够从很少的带标注的切片中推广到非常精确的三维分割,而不需要太多的标注工作。(2)全自动分割已经有一个在具有代表性的训练集上(带注释的切片)进行训练得到的网络,用户可以使用这个网络在没有注释的体积卷上运行,来得到整个三维体的分割。
通道数翻倍的时机和反卷积操作。在2D Unet中,通道数翻倍的时机在下采样后的第一次卷积时;而在3D U-Net中,通道数翻倍发生在下采样或上采样前的卷积中。对于反卷积操作,区别在于通道数是否减半,2D U-Net中通道数减半,而3D U-Net中通道数不变。
使用Batch Normalization来加快收敛和避免网络结构的瓶颈。
使用了旋转、缩放和灰度增强等数据增强方法,此外在训练 ...

语义分割综述
一、语义分割、实例分割和全景分割
1、通俗理解(1)语义分割:分割出每个类别,即对图片的每个像素做分类
(2)实例分割:分割出每个实例(不含背景)
(3)全景分割:分割出每个实例(含背景)二、语义分割的方法1、传统机器学习方法
传统方法Pipeline: 特征 + forst/boost + CRF
劣势:单个学习分类器只针对单一的类别设计,导致分割类别多时有计算复杂度高和训练难度大的问题(如像素级的决策树分类,参考TextonForest以及Random Forest based classifiers)
2、深度学习方法
卷积神经网络:FCN、DeepLab-V1(2014), SegNet、UNet(2015), DeepLab-V2(2016)…(一般都是在分类网络上进行精调,分类网络为了能获取更抽象的特征分层,采取了Conv+pool堆叠的方式,这导致了分辨率降低,丢失了很多信息,这对分割任务来说肯定是不好的,因为分割是对每一个像素进行分类,会造成定位精度不高。但同时更高层的特征对于分类又很重要。如何权衡这两者呢?)
Encoder-Decoder方法:与经典的F ...
一些常用的网络结构中的Module和Block
Group Convolution
分组卷积(来自AlexNet)详解: https://www.jianshu.com/p/a936b7bc54e3
Inception Module
多尺度特征提取再融合(来自Inception-V1)
Residual Block
残差结构(来自ResNet,先降维再升维)
Element-wise Addition
更激进的密集连接机制(来自ResNet)
BottleNeck
瓶颈结构(来自ResNet)
Channel-wise Concatenation
实现特征重用,提升效率(来自DenseNet)
Inverted Residual Block
倒残差结构(来自MobileNet-V2,先升维再降维)
Input
Operator
Output
H×W×tK
1×1 conv2d, ReLU6
H×W×tK
H×W×tK
3×3 dwise s=s, ReLU6
H/s×W/s×tK
H/s×W/s×tK
linear 1×1 conv2d
H/s ...
Pytorch中常用的Transforms方法
一、裁剪——Crop1、随机裁剪:transforms.RandomCrop1class torchvision.transforms.RandomCrop(size, padding=None, pad_if_needed=False, fill=0, padding_mode=‘constant’)
功能:依据给定的size随机裁剪
参数:size - (sequence or int),若为sequence,则为(h,w),若为int,则(size,size)padding - (sequence or int, optional),此参数是设置填充多少个pixel。当为int时,图像上下左右均填充int个,例如padding=4,则上下左右均填充4个pixel,若为3232,则会变成4040。当为sequence时,若有2个数,则第一个数表示左右扩充多少,第二个数表示上下的。当有4个数时,则为左,上,右,下。fill - (int or tuple) 填充的值是什么(仅当填充模式为constant时有用)。int时,各通道均填充该值,当长度为3的tuple时,表示R ...