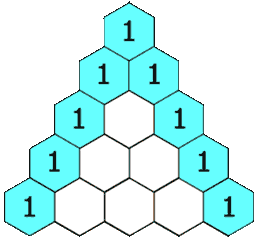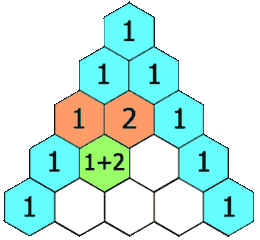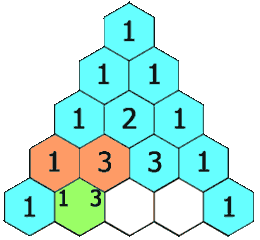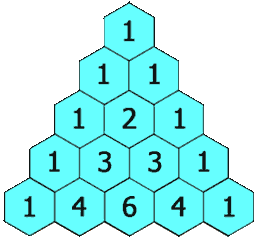
defgenerate(self, numRows): ret = [[1]*i for i inrange(1, numRows+1)] for i inrange(2, numRows): for j inrange(1, i): ret[i][j] = ret[i-1][j-1] + ret[i-1][j] return ret
pre = cur = head while pre.next != head: pre = cur cur = cur.next if pre.val <= insertVal and cur.val >= insertVal: break if pre.val > cur.val and (insertVal >= pre.val or insertVal <= cur.val): break pre.next = insertNode insertNode.next = cur return head
defpreorderTraversal(self, root): ret = [] if root == None: return ret ret += [root.val] ret += self.preorderTraversal(root.left) ret += self.preorderTraversal(root.right) return ret
迭代算法(用栈实现,左、右链入栈)
1 2 3 4 5 6 7 8 9 10 11 12 13 14
defpreorderTraversal(self, root): ret = [] if root == None: return []
stack = [root] while(stack): node = stack.pop() ret.append(node.val) if node.right: # 先压入右子树使其后出栈 stack.append(node.right) if node.left: stack.append(node.left) return ret
definorderTraversal(self, root): ret = [] if root == None: return ret ret += self.inorderTraversal(root.left) ret += [root.val] ret += self.inorderTraversal(root.right) return ret
迭代算法(用栈实现,左链入栈)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
definorderTraversal(self, root): ret = [] if root == None: return ret
defpostorderTraversal(self, root): ret = [] if root == None: return ret ret += self.postorderTraversal(root.left) ret += self.postorderTraversal(root.right) ret += [root.val] return ret
deflevelOrder(self, root): if root == None: return []
ret = [[]] queue = [[root, 1]] while(queue): node, depth = queue.pop(0) ret[depth-1].append(node.val) if node.left: queue.append([node.left, depth+1]) iflen(ret) < depth+1: ret += [[]] if node.right: queue.append([node.right, depth+1]) iflen(ret) < depth+1: ret += [[]] return ret
迭代算法(BFS 模板的意思)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
deflevelOrder(self, root): if root == None: return []
ret = [] queue = [root] while(queue): temp = [] n = len(queue) for i inrange(n): node = queue.pop(0) temp.append(node.val) if node.left: queue.append(node.left) if node.right: queue.append(node.right) ret.append(temp) return ret
迭代算法(用队列实现,不分层输出,不适用于解本题,仅供参考)
1 2 3 4 5 6 7 8 9 10 11 12 13 14
deflevelOrder(self, root): ret = [] if root == None: return ret
queue = [root] while(queue): node = queue.pop(0) ret.append(node.val) if node.left: queue.append(node.left) if node.right: queue.append(node.right) return ret
哈夫曼树
并查集
图
基本概念
(1)邻接矩阵 (2)邻接表 (3)十字链表 (4)邻接多重表
广度优先遍历
深度优先遍历
最小生成树
最短路径
拓扑排序
拓扑排序的实现:对于有向图 G,每次访问 G 中入度为 0 的节点,访问得到的序列即为拓扑排序的结果。 (注意:每一轮中入度为 0 的节点不唯一,因此拓扑排序的结果也不唯一。)
for sequence in sequences: for i inrange(len(sequence)-1): dst[sequence[i]].append(sequence[i+1]) inDegrees[sequence[i+1]] += 1
queue = [i for i inrange(1, n+1) ifnot inDegrees[i]] while queue: iflen(queue) >= 2: returnFalse u = queue.pop(0) for v in dst[u]: inDegrees[v] -= 1 ifnot inDegrees[v]: queue.append(v) returnTrue
defrotate(self, nums: List[int], k: int) -> None: """ Do not return anything, modify nums in-place instead. """ n = len(nums) k = k % n count = gcd(k, n) for start inrange(count): cur = start pre = nums[start] while(True): next = (cur + k) % n nums[next], pre = pre, nums[next] cur = next if start == cur: break
defremoveNthFromEnd(self, head, n): if head == Noneor head.next == None: # 链表元素个数小于等于 1 returnNone fast, slow = head, head for i inrange(n): # 快指针先移动 n 步 fast = fast.next if fast == None: # 若快指针遍历至链表末尾,倒数第 n 个则为链表第一个元素 return head.next while(fast.next): # 快慢指针同时移动,直至快指针移动到链表末尾 fast = fast.next slow = slow.next slow.next = slow.next.next return head
defcheckInclusion(self, s1: str, s2: str) -> bool: n, m = len(s1), len(s2) cnt1 = [0]*26 cnt2 = [0]*26 for i inrange(n): cnt1[ord(s1[i])-ord('a')] += 1 for i inrange(m-n+1): if i == 0: for j inrange(n): cnt2[ord(s2[i+j])-ord('a')] += 1 if cnt1 == cnt2: returnTrue else: cnt2[ord(s2[i-1])-ord('a')] -= 1 cnt2[ord(s2[i+n-1])-ord('a')] += 1 if cnt1 == cnt2: returnTrue returnFalse
defmaxAreaOfIsland(self, grid: List[List[int]]) -> int: self.m, self.n = len(grid), len(grid[0]) self.dire = [[-1, 0], [1, 0], [0, -1], [0, 1]] self.flag = [[0]*self.n for _ inrange(self.m)] self.grid = grid ret = 0 for i inrange(self.m): for j inrange(self.n): if self.grid[i][j] == 1and self.flag[i][j] == 0: area = self.bfs(i, j) if area > ret: ret = area return ret
defbfs(self, x, y): area = 0 queue = [[x, y]] while queue: x, y = queue.pop(0) for i inrange(4): dstX = x + self.dire[i][0] dstY = y + self.dire[i][1] if dstX >= 0and dstX < self.m and dstY >= 0and dstY < self.n: if self.grid[dstX][dstY] == 1and self.flag[dstX][dstY] == 0: area += 1 queue.append([dstX, dstY]) self.flag[dstX][dstY] = 1 return area if area else1
defbfs(self, x, y): area = 0 queue = [[x, y]] while queue: x, y = queue.pop(0) for i inrange(4): dstX = x + self.dire[i][0] dstY = y + self.dire[i][1] if dstX >= 0and dstX < self.m and dstY >= 0and dstY < self.n and self.grid[dstX][dstY] == 1: area += 1 queue.append([dstX, dstY]) self.grid[dstX][dstY] = 0 return area if area else1
defupdateMatrix(self, mat: List[List[int]]) -> List[List[int]]: m, n = len(mat), len(mat[0]) ret = [[-1]*n for _ inrange(m)] queue = [] for i inrange(m): for j inrange(n): if mat[i][j] == 0: queue.append([i, j]) ret[i][j] = 0
step = 1 while queue: k = len(queue) temp = [] for i inrange(k): x, y = queue.pop(0) for dx, dy in [[x, y-1], [x, y+1], [x-1, y], [x+1, y]]: if dx >= 0and dx < m and dy >= 0and dy < n: if mat[dx][dy] == 1: ret[dx][dy] = step mat[dx][dy] = 0 temp.append([dx, dy]) queue = temp step += 1
good = {num: [] for num in nums2} # 上等马出战对应~ inferior = [] # 下等马集合! index = 0 for num1 in nums1: if num1 > sort2[index]: # 找到最小的“上等马” good[sort2[index]].append(num1) # 用数组存储避免 num2 中有相同元素 index += 1# 更新 num2 的最小元素 else: inferior.append(num1) # 否则视为“下等马”
for key in good.keys(): if good[key] == []: good[key].append(inferior.pop(0)) # 下等马按顺序弹出匹配
for i inrange(n): # 按照匹配结果更新 num1 的排序 if good[nums2[i]]: nums1[i] = good[nums2[i]].pop(0) else: nums1[i] = inferior.pop(0)
deflengthOfLIS(self, nums): dp = [0]*(len(nums)) ret = 1 for i inrange(len(nums)): dp[i] = 1 for j inrange(i): if nums[i] > nums[j]: dp[i] = max(dp[j]+1, dp[i]) if dp[i] > ret: ret = dp[i] return ret
对于二进制串 n = 11000010100101000001111010011101,对 n 的每一位进行以下操作: 1)初始化 ret = 0; 2)将 ret 左移空出最后一位; 3)通过按位 或 运算将 n 的最后一位(n & 1)加到 ret 的最后一位上; 4)再将 n 右移去掉最后一位。 00000000000000000000000000000000 or 1 = 00000000000000000000000000000001 00000000000000000000000000000010 or 0 = 00000000000000000000000000000010 00000000000000000000000000000100 or 1 = 00000000000000000000000000000101 00000000000000000000000000001010 or 1 = 00000000000000000000000000001011 00000000000000000000000000010110 or 1 = 00000000000000000000000000010111 …… 01011100101111000001010010100000 or 1 = 01011100101111000001010010100001 10111001011110000010100101000010 or 1 = 10111001011110000010100101000011
1 2 3 4 5 6 7 8
classSolution: defreverseBits(self, n: int) -> int: ret = 0 for i inrange(32): lastBit = n & 1 ret = ret << 1 | lastBit n = n >> 1 return ret