Transformer系列的简单整理(挖坑)
什么是Transformer?
Attention Mechanism
Self Attention
Multi-Head Attention
Transformer
Paper: Attention is not all you need: pure attention loses rank doubly exponentially with depth[NeurIPS 2017]
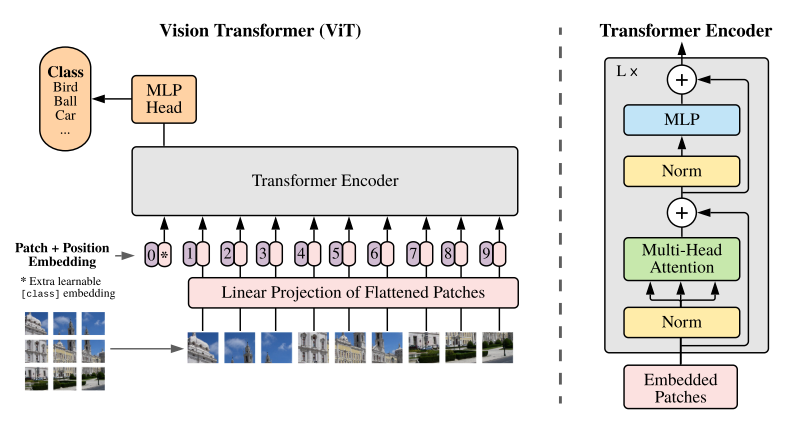
Vision Transformer
ViT
Paper: An Image Is Worth 16X16 Words: Transformers for Image Recognition at Scale[ICLR 2021]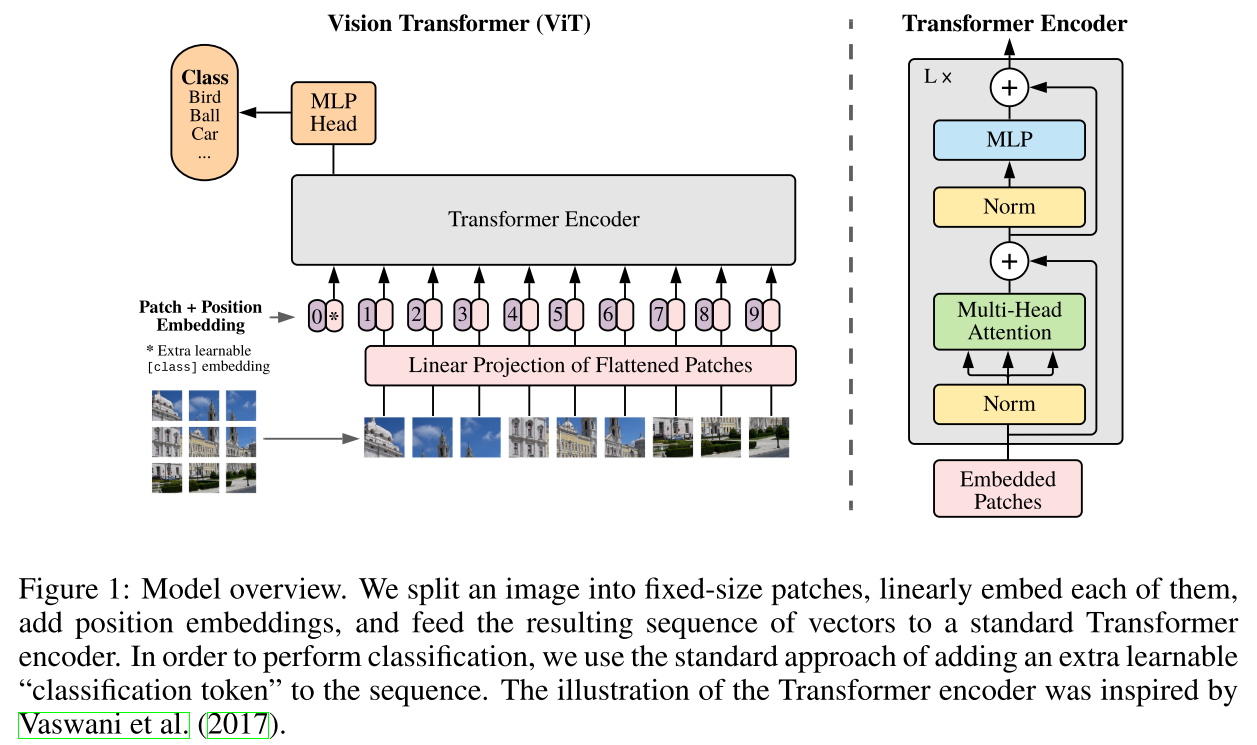
DETR
CrossViT
Paper: CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classificatio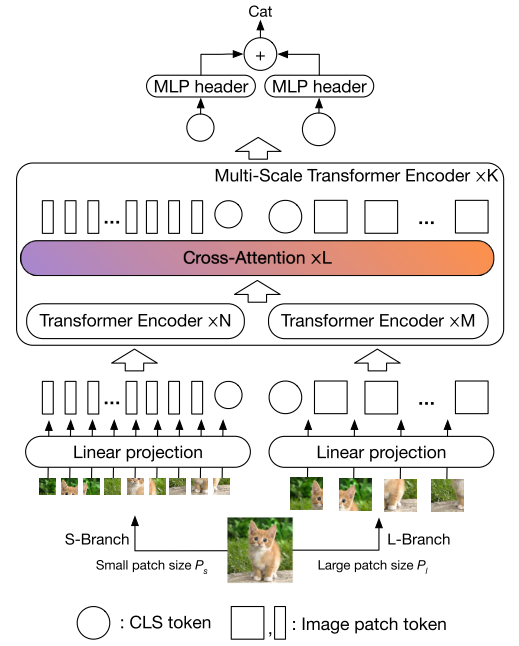
MViT
Paper: Multiscale Vision Transformer
Codes: https://github.com/facebookresearch/SlowFast/tree/master/projects/mvit
Swin-Transformer
Paper: Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
SETR
Paper: Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers[CVPR 2021]
Codes: SETR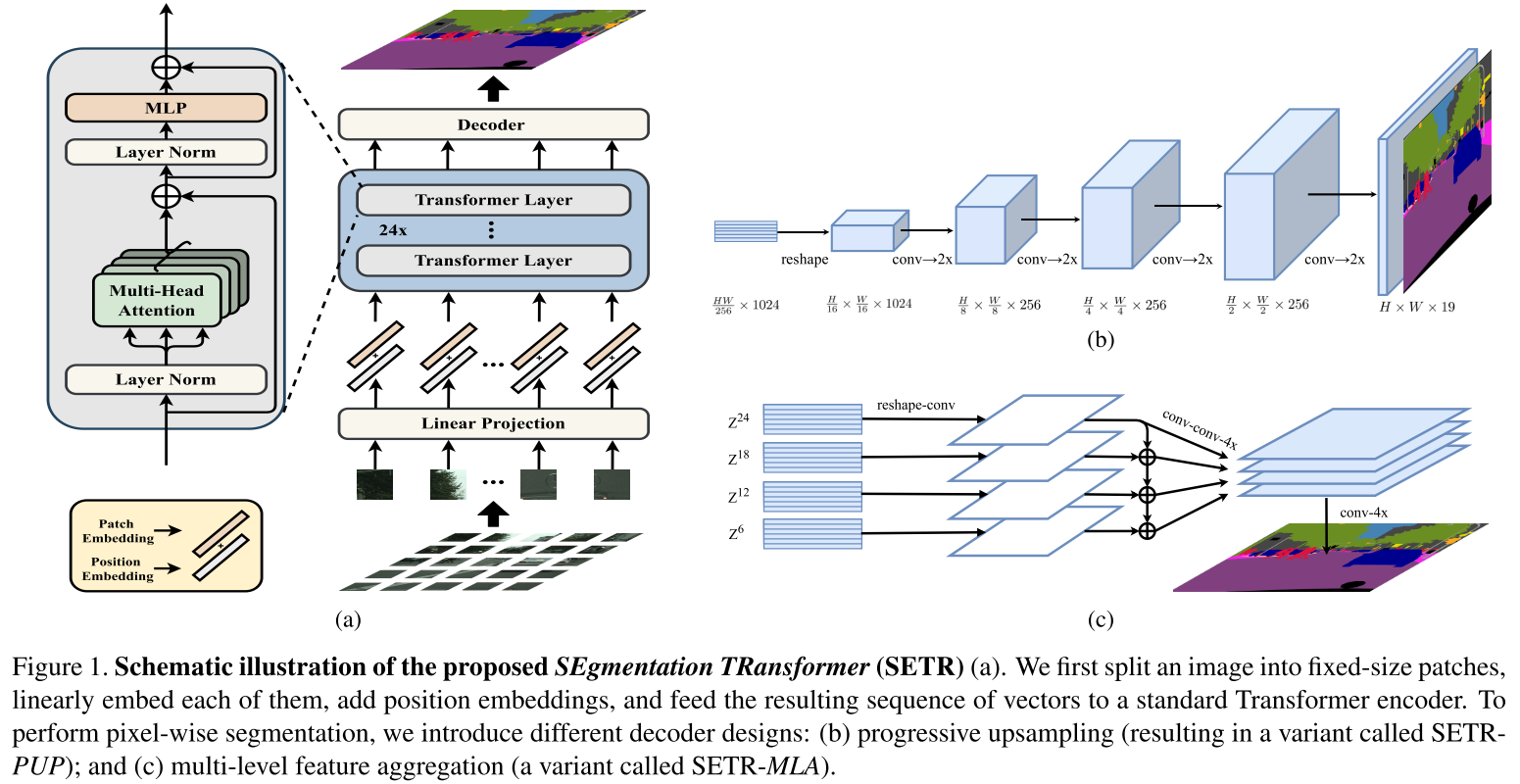
Segmenter
Paper: Segmenter: Transformer for Semantic Segmentation
Codes: Segmenter
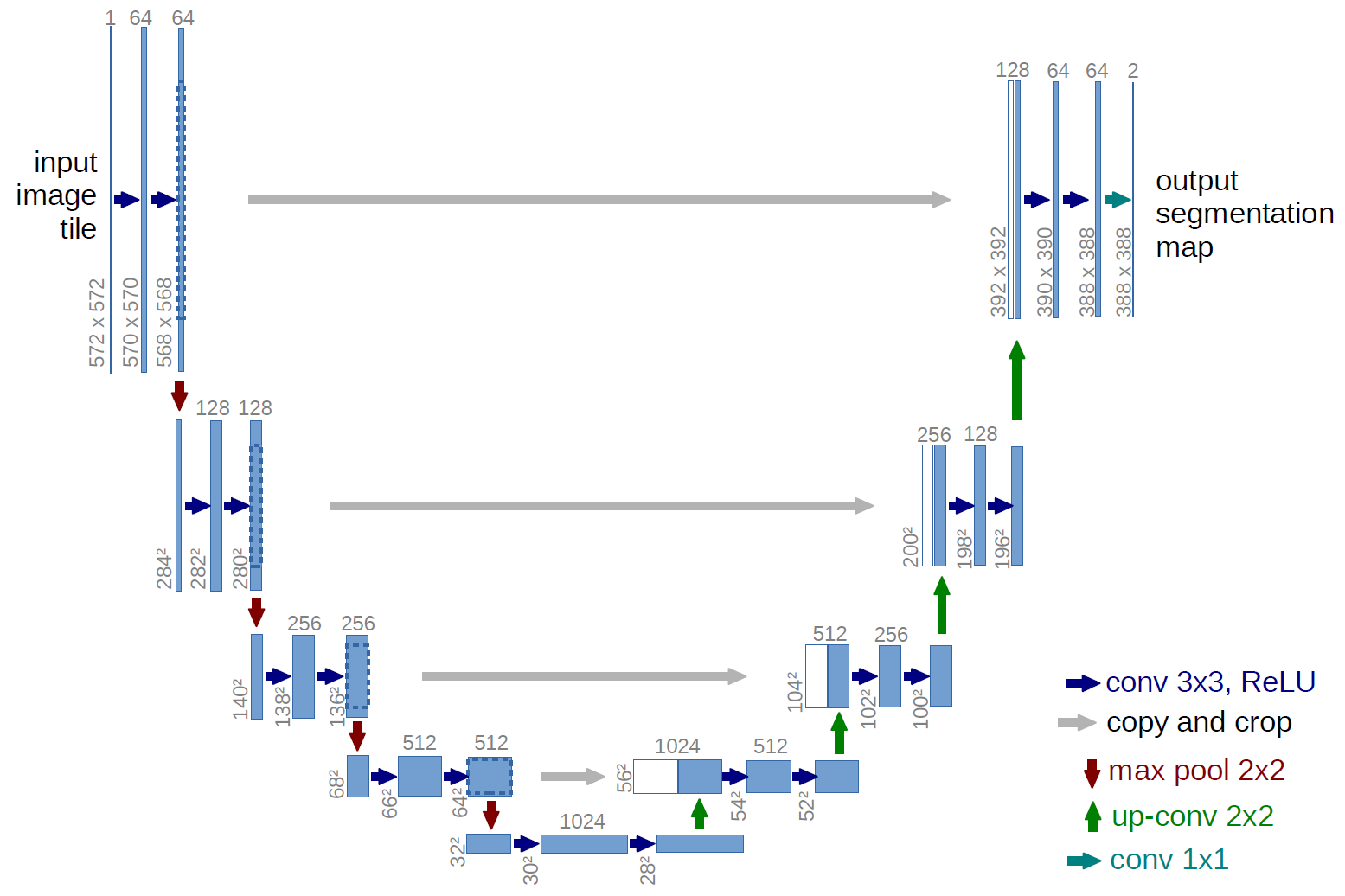
医学图像中的Transformer
TransU-Net
Paper: TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation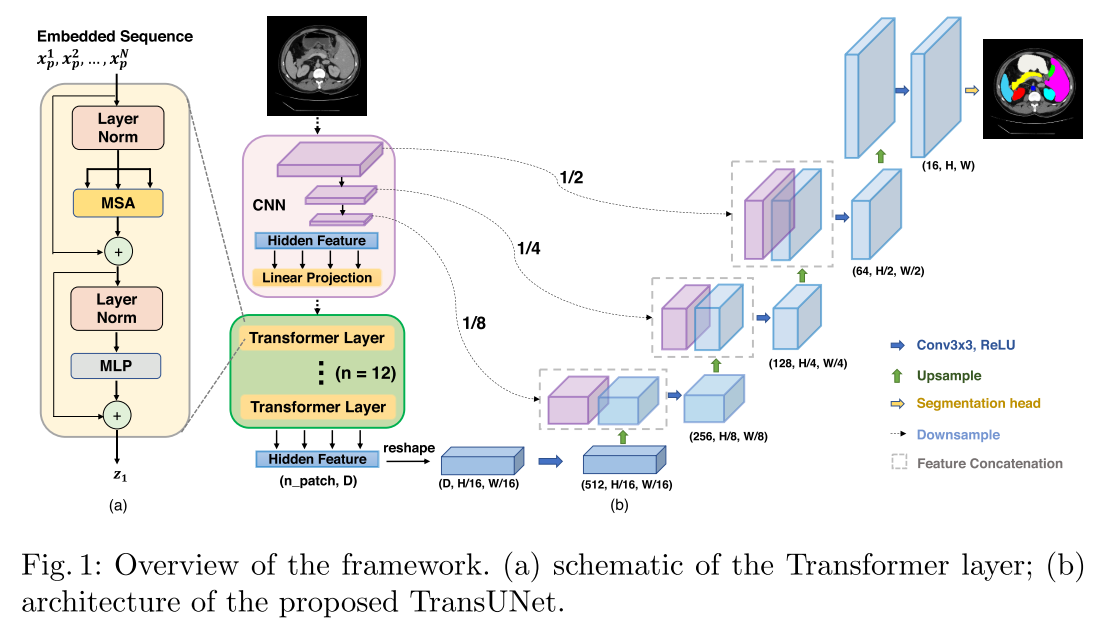
U-Net Transformer
Paper: U-Net Transformer: Self and Cross Attention for Medical Image Segmentation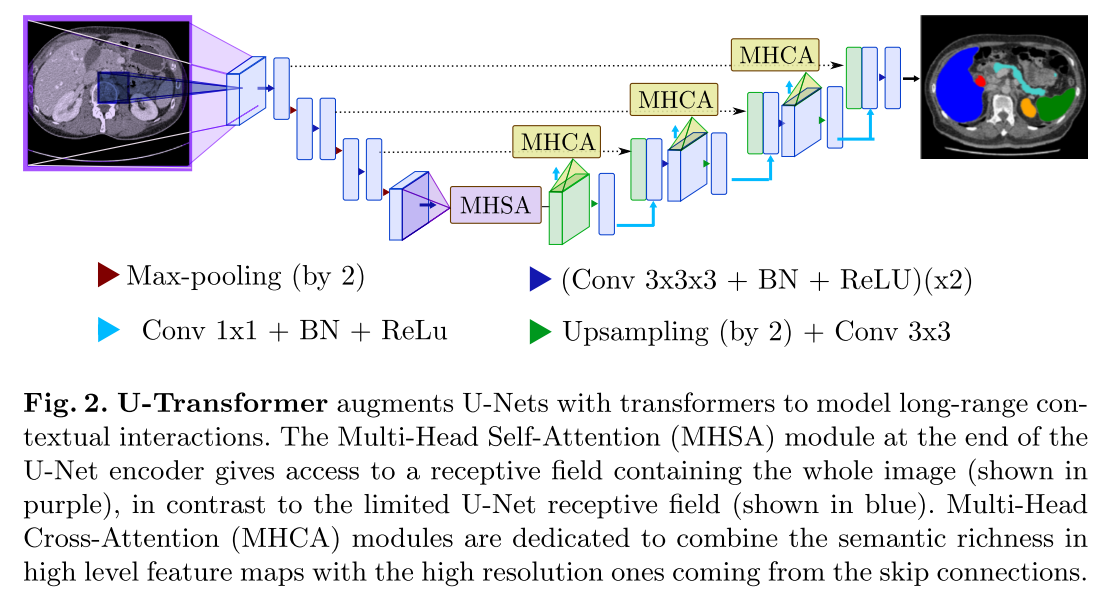
Medical Transformer(MedT)
Paper: Medical Transformer: Gated Axial-Attention for Medical Image Segmentation[MICCAI 2021]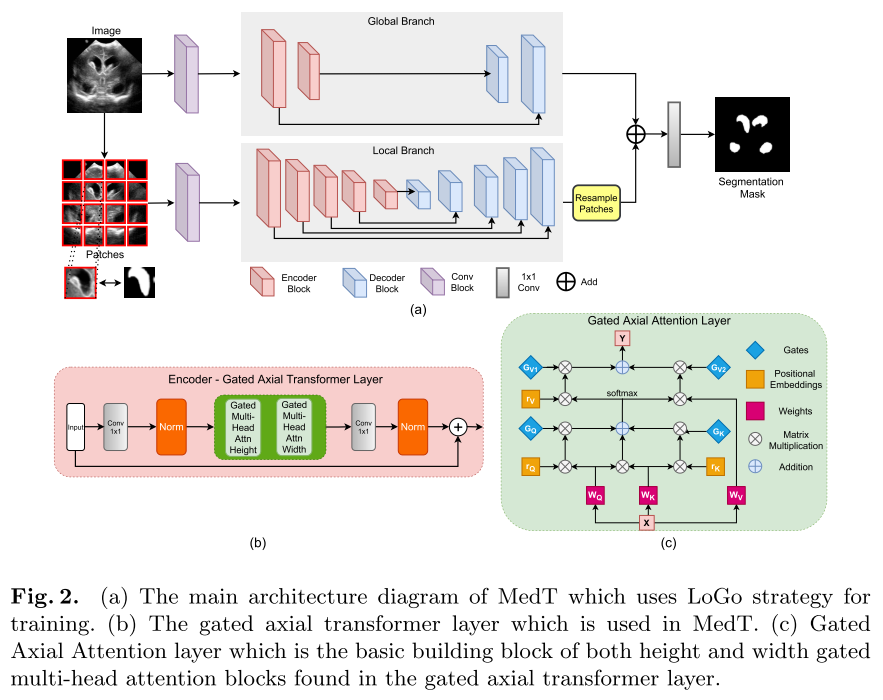
TransBTS
UNETR
TransFuse
Paper: TransFuse: Fusing Transformers and CNNs for Medical Image Segmentation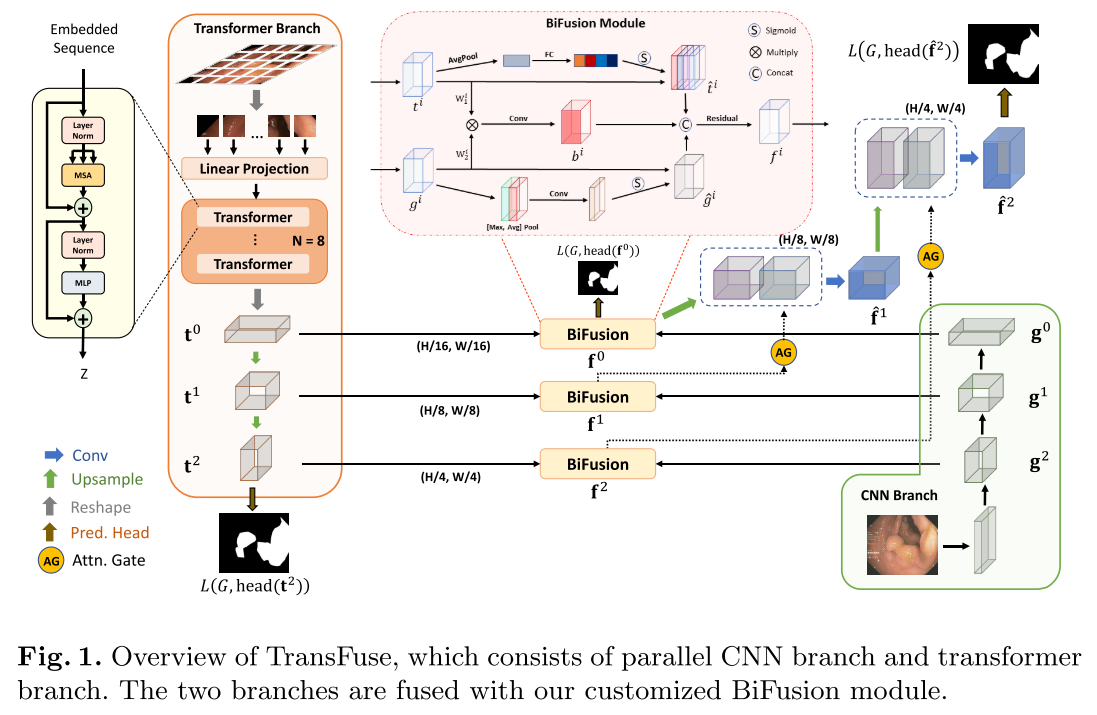
SegTran
Paper: Medical Image Segmentation Using Squeeze-and-Expansion Transformers[IJCAI 2021]
Codes: segtran
Trans2Seg
Swin-Unet
Paper: Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation
Codes: Swin-Unet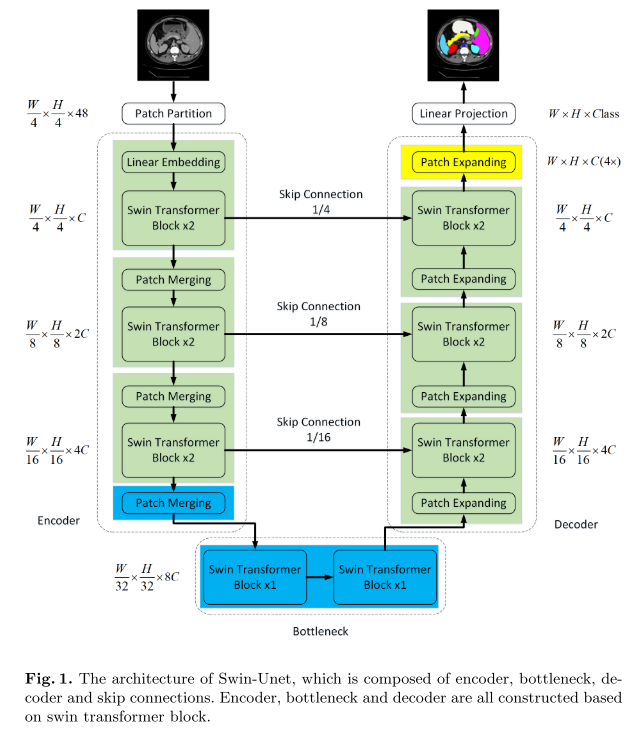
DS-TransUNet
UTNet
[MICCAI 2021]
PNS-Net
[MICCAI 2021]