
语义分割综述
一、语义分割、实例分割和全景分割

1、通俗理解
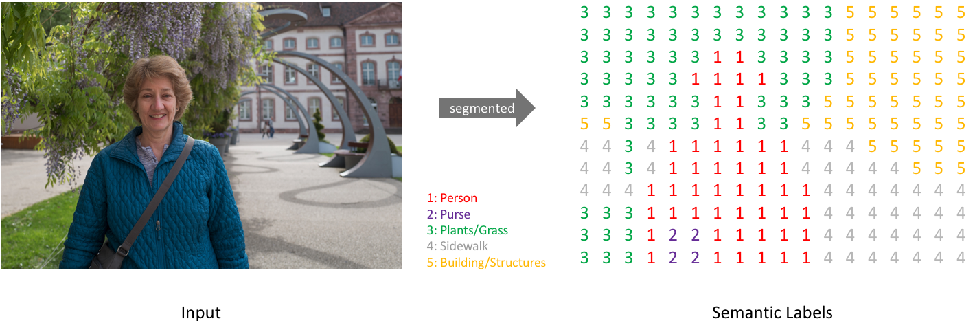
(1)语义分割:分割出每个类别,即对图片的每个像素做分类
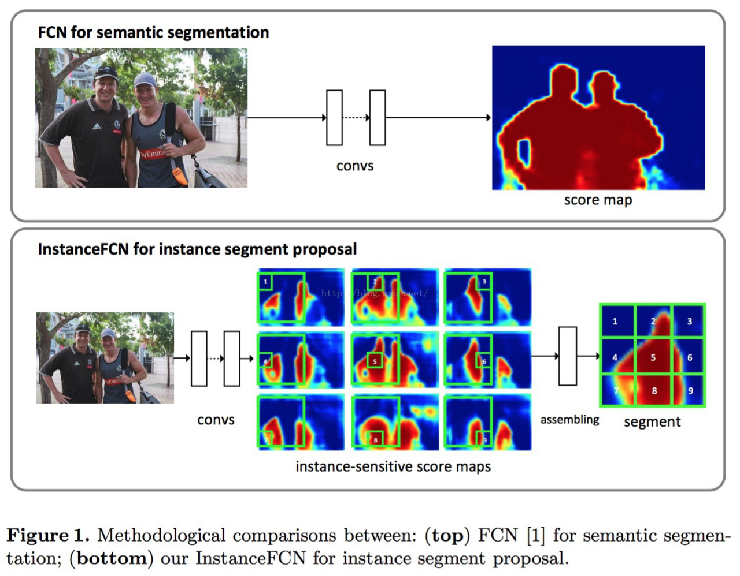
(2)实例分割:分割出每个实例(不含背景)
(3)全景分割:分割出每个实例(含背景)
二、语义分割的方法
1、传统机器学习方法
- 传统方法Pipeline: 特征 + forst/boost + CRF
- 劣势:单个学习分类器只针对单一的类别设计,导致分割类别多时有计算复杂度高和训练难度大的问题
(如像素级的决策树分类,参考TextonForest以及Random Forest based classifiers)
2、深度学习方法
- 卷积神经网络:FCN、DeepLab-V1(2014), SegNet、UNet(2015), DeepLab-V2(2016)…
(一般都是在分类网络上进行精调,分类网络为了能获取更抽象的特征分层,采取了Conv+pool堆叠的方式,这导致了分辨率降低,丢失了很多信息,这对分割任务来说肯定是不好的,因为分割是对每一个像素进行分类,会造成定位精度不高。但同时更高层的特征对于分类又很重要。如何权衡这两者呢?) - Encoder-Decoder方法:与经典的FCN中的Skip-Connection思想类似,Encoder为分类网络,用于提取特征,而Decoder则是将Encoder的先前丢失的空间信息逐渐恢复,Decoder的典型结构有U-Net/Segnet/RefineNet,该类方法虽然有一定的效果,能恢复部分信息,但毕竟信息已经丢失了,不可能完全恢复。
- Dialed FCN方法:Deeplab-V1提出的方法,将VGG的最后的两个Pool层步长置为1,这样网络的输出分辨率从1/32变为1/8。可以保留更多的细节信息,同时也丢掉了复杂的Decoder结构,但这种方法计算量大。
- 注:DeepLab-V3将Encoder-Decoder方法与Dialed FCN方法结合,达到了非常好的效果,同时计算量也非常巨大
三、语义分割的难点
- 数据集问题:需要精确的像素级标注
- 计算资源问题:要求高精度 -> 深层网络 -> 分割预测每一个像素点 -> 要求Feature Map有尽量高的分辨率 -> 计算资源不足
- 精细分割:(1)大类别、小目标:分割精度高 (2)小类别、小目标:轮廓太小 -> 分割精度低
- 上下文信息:忽略上下文信息会造成 一个类别目标分成多个类别part、不同类别目标分成相同类别
(什么是上下文信息?察觉并能应用能够影响场景和图像中的对象的一些或全部信息,通俗理解为像素以及周边像素的联系)
四、语义分割模型
- 一般的语义分割架构可以被认为是一个编码器-解码器网络。
编码器通常是一个预训练的分类网络,像VGG、ResNet,然后是一个解码器网络。
这些架构不同的地方主要在于解码器网络。解码器的任务是将编码器学习到的可判别特征(较低分辨率)从语义上投影到像素空间(较高分辨率),以获得密集分类。 - 不同于分类任务中网络的最终结果(对图像分类的概率)是唯一重要的事,语义分割不仅需要在像素级有判别能力,还需要有能将编码器在不同阶段学到的可判别特征投影到像素空间的机制。不同的架构采用不同的机制(跳跃连接、金字塔池化等)作为解码机制的一部分。
1、FCN
(1)Architecture
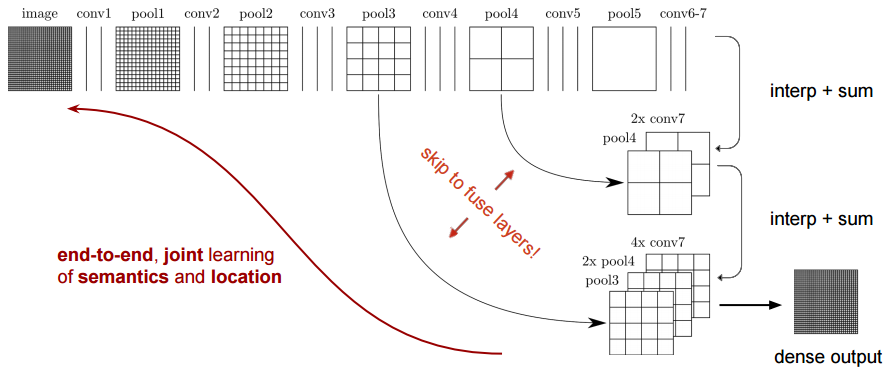
(2)Contribution
- 为语义分割引入了端到端的全卷积网络,并流行开来
- 重新利用ImageNet的预训练网络用于语义分割
- 使用反卷积层代替线性插值法进行上采样
- 引入跳跃连接来改善上采样粗糙的像素定位
2、DeconvNet
(1)Architecture
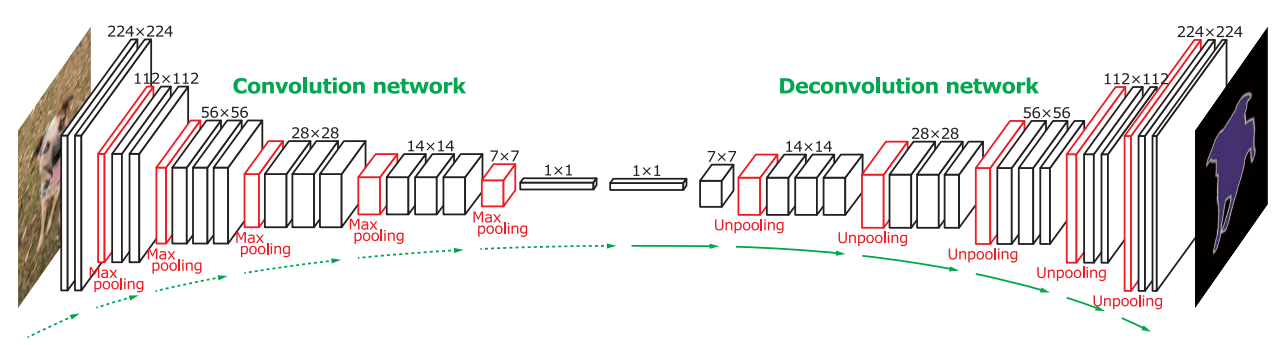
(2)Contribution
- UpPooling过程中与SegNet类似,但除了还原记录的Pooling Indices之外,其他位置均补0
3、SegNet
(1)Architecture
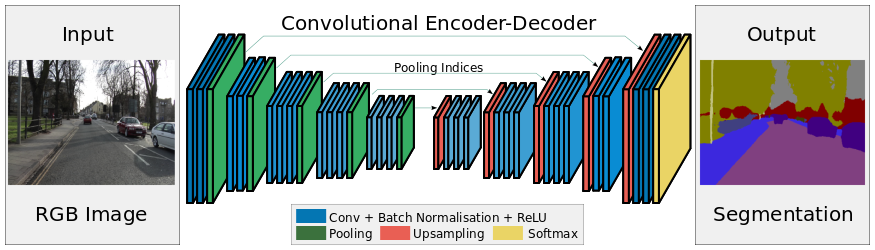
(2)Contribution
- 将池化层结果应用到译码过程
- 引入了更多的编码信息
- 使用的是Pooling Indices,而不是直接复制特征,只是将编码过程中Pool的位置记下来,在UpPooling是使用该信息进行Pooling
4、UNet
(1)Architecture
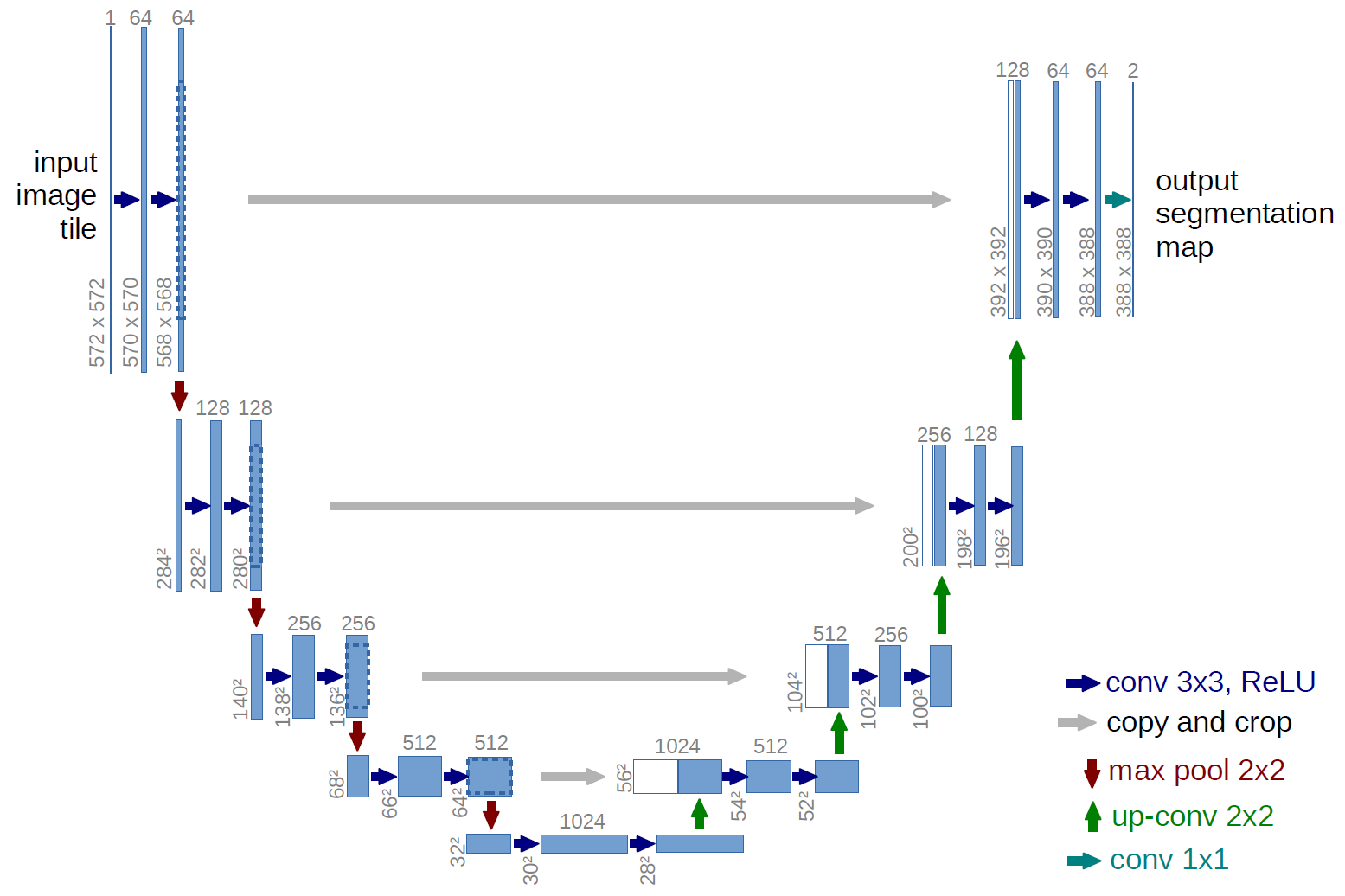
(2)Contribution
- 更规整的网络结构
- 通过将编码器的每层结果拼接到译码器中得到更好的结果
5、PSPNet
(1)Architecture
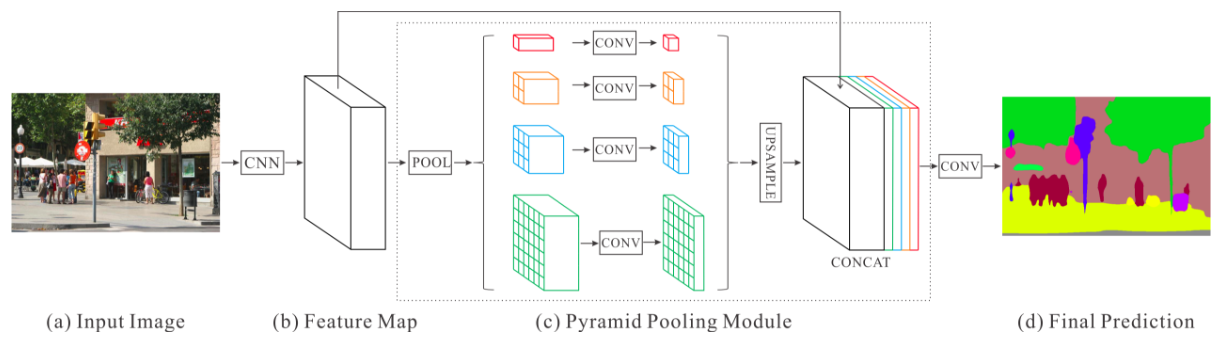
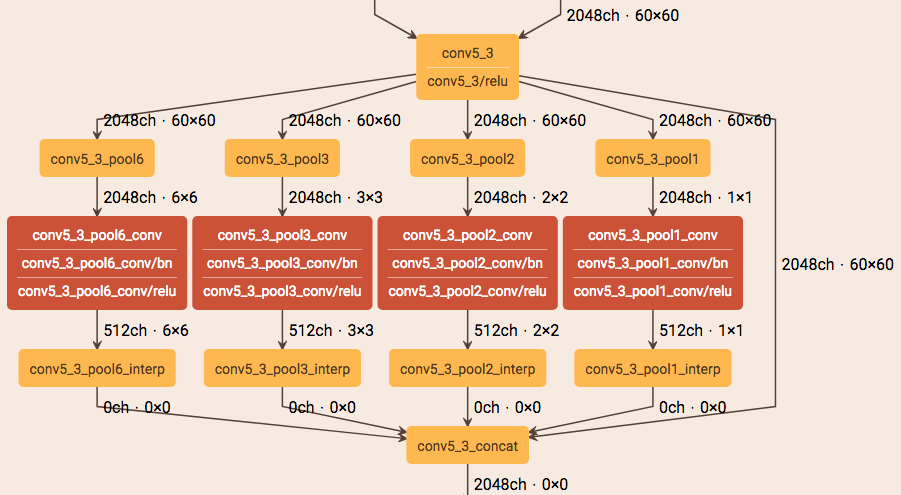
(2)Contribution
- 提出了金字塔池化模块来聚合图片信息
- 使用附加的损失函数
6、RefineNet
(1)Architecture
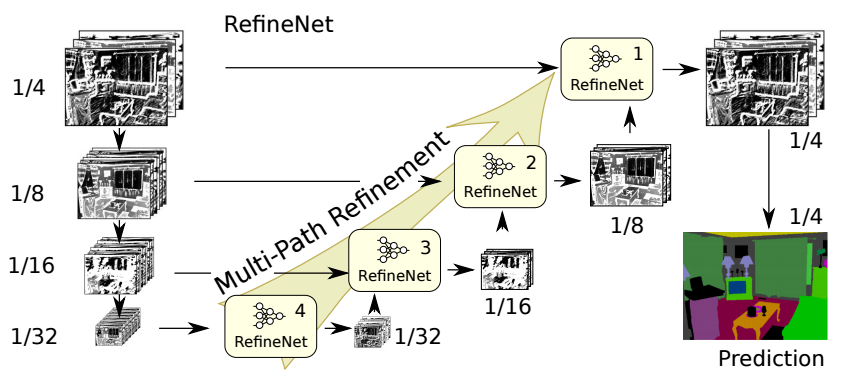
(2)Contribution
- 精心设计的译码模块
- 所有模块遵循残差连接设计
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 “干杯( ゚-゚)っロ”!
相关推荐

评论