
CV Papers
read-paper-list
semantic segmentation/object detection/light-weight network/instance segmentation
Deep-base-network
- ImageNet Classification with Deep Convolutional Neural Networks(AlexNet)
- Very Deep Convolutional Networks For Large-Scale Image Recognition(VGG)
- Network In Network(NIN)
- Going Deeper with Convolutions(GoogleNet)
- Deep Residual Learning for Image Recognition(ResNet)
- Densely Connected Convolutional Networks(DenseNet)
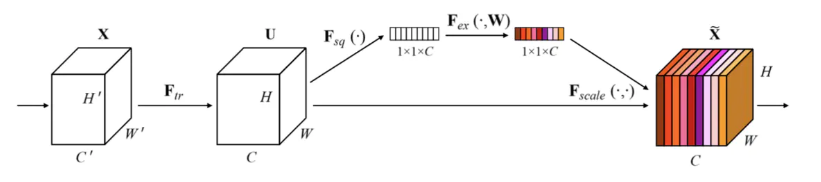
- Squeeze-and-Excitation Networks(SENet)
- Gather-Excite: Exploiting Feature Context in Convolutional Neural Networks(GENet)
- Non-local Neural Networks
- Convolutional Neural Networks with layer reuse(LruNet)
- GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond(GCNet)
- Rethinking ImageNet Pre-training
- Multi-Stage HRNet: Multiple Stage High-Resolution Network for Human Pose Estimation
light-weight network
- SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and< 0.5 MB model size(SqueezeNet)
- Mobilenets: Efficient convolutional neural networks for mobile vision applications(Mobilenet V1)
- ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices(ShuffleNet V1)
- Inverted Residuals and Linear Bottlenecks: Mobile Networks for Classification, Detection and Segmentation(Mobilenet V2)
- SqueezeNext: Hardware-Aware Neural Network Design(SqueezeNext)
- CondenseNet: An Efficient DenseNet using Learned Group Convolutions(CondenseNet)
- Pelee: A Real-Time Object Detection System on Mobile Devices(PeleeNet)
- ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design(ShuffleNet V2)
- ESPNet: Efficient Spatial Pyramid of Dilated Convolutions for Semantic Segmentation(ESPNet)
- ChannelNets: Compact and Efficient Convolutional Neural Networks via Channel-Wise Convolutions(ChannelNets)
- ESPNetv2: A Light-weight, Power Efficient, and General Purpose Convolutional Neural Network(ESPNetV2)
- Interleaved Group Convolutions for Deep Neural Networks(IGCV1)
- IGCV2: Interleaved Structured Sparse Convolutional Neural Networks(IGCV2)
- IGCV3: Interleaved Low-Rank Group Convolutions for Efficient Deep Neural Networks(IGCV3)
- MnasNet: Platform-Aware Neural Architecture Search for Mobile(MnasNet)
- FBNet: Hardware-Aware Efficient ConvNet Design via Differentiable Neural Architecture Search(FBNet)
- EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks(EfficientNet)
- DiCENet: Dimension-wise Convolutions for Efficient Networks(DiCENet)
- Hybrid Composition with IdleBlock: More Efficient Networks for Image Recognition
- An Energy and GPU-Computation Efficient Backbone Network for Real-Time Object Detection
semantic segmentation
- Fully Convolutional Networks for Semantic Segmentation(FCN)
- SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation(SegNet)
- U-Net: Convolutional Networks for Biomedical Image Segmentation(UNet)
- Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs(Deeplab v1)
- DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution,and Fully Connected CRFs(Deeplab v2)
- Understanding Convolution for Semantic Segmentation(DUC)
- Pyramid Scene Parsing Network(PSPNet)
- Large Kernel Matters – Improve Semantic Segmentation by Global Convolutional Network(GCN)
- Rethinking Atrous Convolution for Semantic Image Segmentation(Deeplab v3)
- DenseASPP for Semantic Segmentation in Street Scenes(DenseASPP)
- Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation(Deeplab v3plus)
- Context Encoding for Semantic Segmentation(EncNet)
- Learning a Discriminative Feature Network for Semantic Segmentation(DFN)
- Smoothed Dilated Convolutions for Improved Dense Prediction(SDC)
- Pyramid Attention Network for Semantic Segmentation(PAN)
- Exploring Context with Deep Structured models for Semantic Segmentation(FeatMap-Net)
- ExFuse: Enhancing Feature Fusion for Semantic Segmentation(ExFuse)
- Dilated Residual Networks(DRN)
- Dual Attention Network for Scene Segmentation(DANet)
- OCNet:Object Context Network for Scene Parsing(OCNet)
- RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation(RefineNet)
- Dense Relation Network: Learning Consistent And Context-Aware Prepresentation For Semantic Image Segmentation(DRN)
- CCNet: Criss-Cross Attention for Semantic Segmentation(CCNet)
- Unified Perceptual Parsing for Scene Understanding(UPerNet)
- Tree-structured Kronecker Convolutional Networks for Semantic Segmentation(TKNet)
- NeuroIoU: Learning a Surrogate Loss for Semantic Segmentation(NeuroIoU)
- Decoders Matter for Semantic Segmentation:Data-Dependent Decoding Enables Flexible Feature Aggregation
- GFF: Gated Fully Fusion for Semantic Segmentation(GFF)
- Learning Fully Dense Neural Networks for Image Semantic Segmentation(FDNet)
- ZigZagNet: Fusing Top-Down and Bottom-Up Context for Object Segmentation(ZigZagNet)
- Adaptive Pyramid Context Network for Semantic Segmentation(APCNet)
- Dense Decoder Shortcut Connections for Single-Pass Semantic Segmentation
- ACFNet: Attentional Class Feature Network for Semantic Segmentation(ACFNet)
- Miss Detection vs. False Alarm: Adversarial Learning for Small Object Segmentation in Infrared Images
- Dual Graph Convolutional Network for Semantic Segmentation
- Global Aggregation then Local Distribution in Fully Convolutional Networks
- Dynamic Multi-scale Filters for Semantic Segmentation
- Unifying Training and Inference for Panoptic Segmentation
- Semantic Flow for Fast and Accurate Scene Parsing
- AlignSeg: Feature-Aligned Segmentation Networks
- Cars Can’t Fly up in the Sky: Improving Urban-Scene Segmentation via Height-driven Attention Networks
- Context Prior for Scene Segmentation
fast/real-time segmentation
- ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation(ENet)
- ICNet for Real-Time Semantic Segmentation(ICNet)
- BiSeNet: Bilateral Segmentation Network for Real-time Semantic Segmentation(BiSeNet)
- LinkNet: Exploiting Encoder Representations for Efficient Semantic Segmentation(LinkNet)
- Rtseg: Real-Time Semantic Segmentation Comparative Study
- Shuffleseg: Real-Time Semantic Segmentation Network(Shuffleseg)
- ESPNet: Efficient Spatial Pyramid of Dilated Convolutions for Semantic Segmentation(ESPNet)
- Light-Weight RefineNet for Real-Time Semantic Segmentation(Light-Weight RefineNet)
- LinkNet: Exploiting Encoder Representations for Efficient Semantic Segmentation(LinkNet)
- D-LinkNet: LinkNet with Pretrained Encoder and Dilated Convolution for High Resolution Satellite Imagery Road Extraction(D-LinkNet)
- CGNet: A Light-weight Context Guided Network for Semantic Segmentation(CGNet)
- Efficient ConvNet for Real-time Semantic Segmentation
- A Comparative Study of Real-time Semantic Segmentation for Autonomous Driving
- ContextNet: Exploring Context and Detail for Semantic Segmentation in Real-time(ContextNet)
- ESPNetv2: A Light-weight, Power Efficient, and General Purpose Convolutional Neural Network(ESPNetV2)
- ShelfNet for Real-time semantic segmentation(ShelfNet)
- ERFNet: Efficient Residual Factorized ConvNet for Real-Time Semantic Segmentation(ERFNet)
- Concentrated-Comprehensive Convolutions for lightweight semantic segmentation(CCCNet)
- DSNet for Real-Time Driving Scene Semantic Segmentation(DSNet)
- Efficient Dense Modules of Asymmetric Convolution for Real-Time Semantic Segmentation(EDANet)
- Fast-SCNN: Fast Semantic Segmentation Network(Fast-SCNN)
- Guided Upsampling Network for Real-Time Semantic Segmentation(GUN)
- In Defense of Pre-trained ImageNet Architecturesfor Real-time Semantic Segmentation of Road-driving Images(SwiftNetRN)
- Residual Pyramid Learning for Single-Shot Semantic Segmentation(RPNet)
- DFANet: Deep Feature Aggregation for Real-Time Semantic Segmentation(DFANet)
- DSNet: An Efficient CNN for Road Scene Segmentation(DSNet)
- Spatial Sampling Network for Fast Scene Understanding
- RGPNET: A REAL-TIME GENERAL PURPOSE SEMANTIC SEGMENTATION
- LiteSeg: A Novel Lightweight ConvNet for Semantic Segmentation
- FASTERSEG: SEARCHING FOR FASTER REAL-TIME SEMANTIC SEGMENTATION
- Partial Order Pruning: for Best Speed/Accuracy Trade-off in Neural Architecture Search
- Customizable Architecture Search for Semantic Segmentation
- Semantic Flow for Fast and Accurate Scene Parsing
- BiSeNet V2: Bilateral Network with Guided Aggregation for Real-time Semantic Segmentation
- ASNet: Aggregated Scale Transformations for Real-Time Semantic Segmentation
Deep object detection
- Rich feature hierarchies for accurate object detection and semantic segmentation(R-CNN)
- SSD: Single Shot MultiBox Detector(SSD)
- Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks(Faster R-CNN)
- Feature Pyramid Networks for Object Detection(FPN)
- Is Faster R-CNN Doing Well for Pedestrian Detection?(RPN_BF)
- Training Region-based Object Detectors with Online Hard Example Mining(OHEM)
- Receptive Field Block Net for Accurate and Fast Object Detection(RFBNet)
- Focal Loss for Dense Object Detection(RetinaNet)
- Single-Shot Refinement Neural Network for Object Detection(RefinDet)
- PVANET: Deep but Lightweight Neural Networks for Real-time Object Detection(PVANET)
- Multi-label learning of part detectors for heavily occluded pedestrian detection(JL-TopS)
- Graininess-aware Deep Feature Learning for Pedestrian Detection(GDFL)
- M2Det: A Single-Shot Object Detector based on Multi-Level Feature Pyramid Network(M2Det)
- CFENet: An Accurate and Efficient Single-Shot Object Detector for Autonomous Driving(CFENet)
- ScratchDet: Training Single-Shot Object Detectors from Scratch(ScratchDet)
- Pooling Pyramid Network for Object Detection(PPN)
- ThunderNet: Towards Real-time Generic Object Detection(ThunderNet)
- Light-Weight RetinaNet for Object Detection
- CornerNet: Detecting Objects as Paired Keypoints(CornerNet)
- Bottom-up Object Detection by Grouping Extreme and Center Points(ExtremeNet)
- RepPoints: Point Set Representation for Object Detection(RepPoints)
- FCOS: Fully Convolutional One-Stage Object Detection(FCOS)
- Mask-Guided Attention Network for Occluded Pedestrian Detection
- Learning Rich Features at High-Speed for Single-Shot Object Detection.
- Dynamic Anchor Feature Selection for Single-Shot Object Detection.
- Contextual Attention for Hand Detection in the Wild
- Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression
- Multiple Anchor Learning for Visual Object Detection
- NETNet: Neighbor Erasing and Transferring Network for Better Single Shot Object Detection
- Is Sampling Heuristics Necessary in Training Deep Object Detectors?
- Rethinking Classification and Localization for Object Detection
- Multiple Anchor Learning for Visual Object Detection
- Learning from Noisy Anchors for One-stage Object Detection
- Learning a Unified Sample Weighting Network for Object Detection∗
- D2Det: Towards High Quality Object Detection and Instance Segmentation
- AugFPN: Improving Multi-scale Feature Learning for Object Detection
- Scale-Equalizing Pyramid Convolution for Object Detection
Face Detection
- S3FD: Single Shot Scale-invariant Face Detector(SFD)
- FaceBoxes: A CPU Real-time Face Detector with High Accuracy(FaceBoxes)
- Detecting Face with Densely Connected Face Proposal Network(DCFPN)
- SSH: Single Stage Headless Face Detector(SSH)
- DSFD: Dual Shot Face Detector(DSFD)
- Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks(MTCNN)
- PyramidBox: A Context-assisted Single Shot Face Detector(PyramidBox)
- SRN:Selective Refinement Network for High Performance Face Detection(SRN)
- Single Shot Attention-Based Face Detector(AFN)
- Improved Selective Refinement Network for Face Detection(ISRN)
- PyramidBox++: High Performance Detector for Finding Tiny Face(PyramidBox++)
- RetinaFace: Single-stage Dense Face Localisation in the Wild(RetinaFace)
Instance segmentation
- Fully Convolutional Instance-aware Semantic Segmentation(FCIS)
- Instance-aware Semantic Segmentation via Multi-task Network Cascades(MNC)
- Mask R-CNN
- Mask Scoring R-CNN
- Path Aggregation Network for Instance Segmentation(PANet)
- RetinaMask: Learning to predict masks improves state-of-the-art single-shot detection for free(RetinaMask)
- YOLACT Real-time Instance Segmentation(YOLACT)
- Parsing R-CNN for Instance-Level Human Analysis(Parsing R-CNN)
- BlitzNet: A Real-Time Deep Network for Scene Understanding(BlitzNet)
- Hybrid Task Cascade for Instance Segmentation(HTC)
- Triply Supervised Decoder Networks for Joint Detection and Segmentation(TripleNet)
- ZigZagNet: Fusing Top-Down and Bottom-Up Context for Object Segmentation(ZigZagNet)
- Bounding Box Embedding for Single Shot Person Instance Segmentation
- Shape-aware Feature Extraction for Instance Segmentation
- Real-Time Panoptic Segmentation from Dense Detections
- EmbedMask: Embedding Coupling for One-stage Instance Segmentation
- PolyTransform: Deep Polygon Transformer for Instance Segmentation
- SOLO: Segmenting Objects by Locations
- RDSNet: A New Deep Architecture for Reciprocal Object Detection and Instance Segmentation
- SSAP: Single-Shot Instance Segmentation With Affinity Pyramid
- YOLACT++:Better Real-time Instance Segmentation
- SAIS: Single-stage Anchor-free Instance Segmentation
- PolarMask: Single Shot Instance Segmentation with Polar Representation
- BANet: Bidirectional Aggregation Network with Occlusion Handling for Panoptic Segmentation
Mutil-task learning
- End-to-End Multi-Task Learning with Attention.
- Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics.
- BlitzNet: A Real-Time Deep Network for Scene Understanding.
- Triply Supervised Decoder Networks for Joint Detection and Segmentation
- Real-time Joint Object Detection and Semantic Segmentation Network for Automated Driving.
- Driving Scene Perception Network: Real-time Joint Detection, Depth Estimation and Semantic Segmentation.
- GradNorm: Gradient Normalization for Adaptive Loss Balancing in Deep Multitask Network
- MultiNet: Real-time Joint Semantic Reasoning for Autonomous Driving
- MultiNet++: Multi-Stream Feature Aggregation and Geometric Loss Strategy for Multi-Task Learning
- Dynamic Task Weighting Methods for Multi-task Networks in Autonomous Driving Systems
- MTI-Net: Multi-Scale Task Interaction Networks for Multi-Task Learning
- AP-MTL: Attention Pruned Multi-task Learning Model for Real-time Instrument Detection and Segmentation in Robot-assisted Surgery
non-deep object detection
- Robust Real-Time Face Detection(Haar+Adaboost)
- Integral Channel Features(ICF)
- The Fastest Pedestrian Detector in the West(FPDW)
- Fast Feature Pyramids for Object Detection(ACF)
- Local Decorrelation for Improved Pedestrian Detection(LDCF)
- Convolutional Channel Features(CCF)
- Informed Haar-like Features Improve Pedestrian Detection(InformedHaar)
- Fast Pedestrian Detection for Mobile Devices(FastCF)
- Pedestrian detection at 100 Frames Per Second(VeryFast)
- To Boost or Not to Boost? On the Limits of Boosted Trees for Object Detection(ACF+/LDCF+)
- Filtered channel features for pedestrian detection(Checkerboard)
- Pedestrian Detection Inspired by Appearance Constancy and Shape Symmetry(NNNF)
- Aggregate Channel Features for Multi-view Face Detection(ACFFace)
- Pedestrian Detection with Spatially Pooled Features and Structured Ensemble Learning(SpatialPooling+)
- BAdaCost: Multi-class Boosting with Costs(BAdaCost)
- Exploring Prior Knowledge for Pedestrian Detection(SCCPriors)
- A Fast, Modular Scene Understanding System using Context-Aware Object Detection(SC-ACF)
- Ten Years of Pedestrian Detection,What Have We Learned?(Katamari)
- How Far are We from Solving Pedestrian Detection?
- What Can Help Pedestrian Detection?
- Taking a Deeper Look at Pedestrians
- Semantic Channels for Fast Pedestrian Detection(MRFC+Semantic)
- Fast Boosting based Detection using Scale Invariant Multimodal Multiresolution Filtered Features
- Learning Multilayer Channel Features for Pedestrian Detection
- Fast and Robust Object Detection Using Visual Subcategories
- Learning to Detect Vehicles by Clustering Appearance Patterns(Subcat)
- Looking at Pedestrians at Different Scales: A Multiresolution Approach and Evaluations(MR-ACF)
- Multiresolution models for object detection
- Face Detection without Bells and Whistles
- Fast Detection of Multiple Objects in Traffic Scenes With a Common Detection Framework
- An Exploration of Why and When Pedestrian Detection Fails
- Discriminative Sub-categorization
Image Stitching
- Automatic Panoramic Image Stitching Using Invariant Features(IJCV2007)
- As-Projective-As-Possible Image Stitching with Moving DLT(APAP)
- Shape-Preserving Half-Projective Warps for Image Stitching(SPHP)
- Adaptive As-Natural-As-Possible Image Stitching(AANAP)
- MAGSAC: marginalizing sample consensus
- MAGSAC++, a fast, reliable and accurate robust estimator
- An Evaluation of Feature Matchers for Fundamental Matrix Estimation
- GMS: Grid-based Motion Statistics for Fast, Ultra-robust Feature correspondence
- Vanishing Point Guided Natural Image Stitching
- Warping Residual Based Image Stitching for Large Parallax
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 “干杯( ゚-゚)っロ”!
相关推荐


评论